PLUS
生成AIコラム
うさぎでもわかるRAGの精度を劇的に向上させる実践ガイド

目次:
はじめに
RAG(Retrieval-Augmented Generation)の導入を検討している皆さん、こんにちは!🐰です。
RAGシステムを構築したものの、期待していた精度が出ない、ハルシネーションが減らない、レスポンスが遅いといった課題に直面していませんか?
この記事では、RAGの精度を向上させるための実践的な手法を、具体的なプロンプト例なども添えつつ、分かりやすく解説します。
専門的な用語なども出てきますが、分からないところがあったら調べたり、AIに聞きながら読み進めていただければと思います。
RAGに関する複雑な調整作業も、AIにある程度お任せできるようにもなっているので、安心してくださいね🐰
RAG成功の2つの重要な真実
まず最初に、RAGで成功するために絶対に知っておくべき2つの重要なポイントをお伝えします。
真実1:RAGの性能は「データの質」で決まる
どんなに高性能なAIモデルを使っても、元となるデータの質が悪ければ良い結果は得られません。これは料理と同じで、どんなに腕の良いシェフでも、旬が過ぎた材料では美味しい料理は作れないうさよ🐰
だからこそ、以下が重要になります
- データの分割方法を最適化する(チャンク分割)
- データのクリーニングを徹底する
- 適切な前処理を行う
真実2:RAGは「継続的な改善」で真価を発揮
RAGは「完璧なシステムを一度で構築する」技術ではありません。むしろ「継続的に改善し続ける」ことで真価を発揮する技術です。
だからこそ、以下が重要になります
- 監視システムでパフォーマンスを常に把握
- 評価指標を設定して改善効果を測定
- PDCAサイクルで着実に品質向上
この2つの真実を踏まえて、具体的な改善手法を見ていきましょう!
いきなり全てを実施するのは難しいと思うので、できるところから試していくのが良いと思います。
RAGとは(サクッと復習)
RAG(検索拡張生成)は、外部データベースから関連情報を検索し、その情報を基に生成AIが回答を作成する手法です。2020年にMeta社が提案し、ハルシネーション問題の解決策として注目されています。
RAGの基本的な流れ
- 検索フェーズ: 質問に関連する情報をデータベースから検索
- 生成フェーズ: 検索結果をコンテキストとして生成AIが回答を作成
従来AIとの主な違い
- 情報源: 学習済み知識のみ → 外部DB検索+学習済み知識
- 情報鮮度: 学習時点で固定 → リアルタイム更新可能
- 回答根拠: 不明確 → 出典付きで明確
RAGを活用して、日々の業務を効率化!
ナレフルチャットの「RAG機能」を活用することで
社内ナレッジを読み込んで正確な回答を行う専用AIを構築できます!
外部には非公開の、社内データベースや顧客の情報をAIに参照・回答させることで
社内の問い合わせ対応や、顧客対応にかかる時間を大幅に削減!
RAGの精度を劇的に向上させる実践手法
RAGシステムの性能は、適切な設計と細かなチューニングによって大幅に改善できます。以下、現場で効果が実証されている手法を体系的に紹介します。
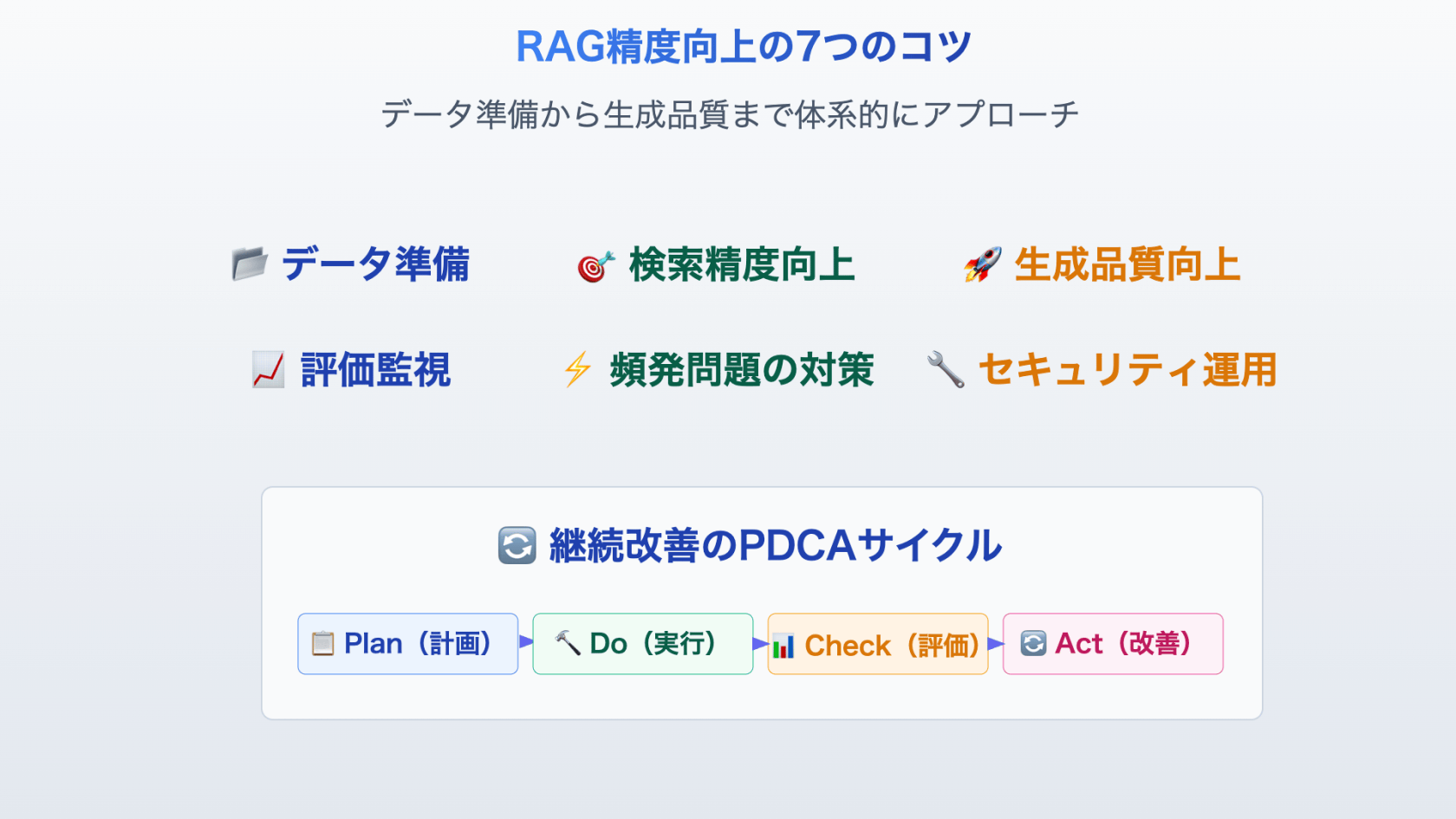
【1】 データ準備・前処理の最適化
チャンク分割戦略の高度化
AIがデータを読みやすくなるように、適切な区間や長さに分割するうさよ~🐰
文章を適切なサイズに分割しないと、AIが必要な情報を見つけられなかったり、文脈が途切れて意味が伝わらなくなったりします。
単純な固定長分割から脱却し、コンテンツの性質に応じた戦略的分割を行います。
用途別最適サイズの設定
- 一般文書: 512〜1024トークン(バランス重視)
- 技術文書: 256〜512トークン(詳細情報の保持)
- FAQ: 128〜256トークン(簡潔性優先)
- 法務文書: 1024トークン以上(文脈の完全性重視)
- コード関連: 512トークン程度(機能単位での分割)
セマンティック分割の実装
文や段落の境界を尊重し、意味的な切れ目で分割することで文脈の損失を防ぎます。具体的には、文章解析ライブラリを活用して文の境界を検出し、指定されたトークン数に近づくまで文を蓄積してからチャンク化します。
オーバーラップ戦略
隣接するチャンク間に10〜20%の重複を設けることで、文脈の継続性を保ちます。特に技術文書では、前後の文脈が重要な場合が多いため、この手法が効果的です。
データクリーニング・正規化
ノイズの多いデータを、AIが理解しやすいきれいなデータに整える作業うさ🐰
データにノイズ(余分な情報や誤った情報)が混じっていると、AIが正しい答えを見つけるのが難しくなります。
高品質なRAGシステムには、徹底的なデータクリーニングが不可欠です。
基本クリーニング
- 重複除去: 完全一致、部分重複、意味的重複の3段階で検出
- ノイズ除去: ヘッダー、フッター、ナビゲーション要素の自動削除
- 空白正規化: 余分な改行、スペース、タブの統一
- 文字エンコード統一: UTF-8への統一とBOM除去
専門用語の正規化
- 略語展開: ドメイン固有の略語辞書を活用した自動展開
- 表記ゆれ統一: 「Web」「ウェブ」「web」などの統一
- 同義語グループ化: 意味的に同じ用語の関連付け
構造化要素の処理
- 表データ: CSV形式に変換し、文脈情報を保持
- コードブロック: シンタックス情報を含めた保存
- リスト項目: 階層構造を維持した変換
メタデータの戦略的付与
- カテゴリ分類: 技術/営業/人事/法務などの業務分野
- 重要度レベル: 緊急度や優先度の数値化
- 更新頻度: 情報の鮮度管理のための分類
- アクセス制御: セキュリティレベルの設定
【2】 検索精度の向上
ハイブリッド検索の実装
キーワード検索とベクトル検索を組み合わせて、「言葉の一致」と「意味の一致」両方で検索するうさ🐰
キーワード検索だけでは同義語を見つけられず、ベクトル検索だけでは固有名詞を正確に見つけられません。両方を組み合わせることで検索の精度が大幅に向上します。
BM25(キーワード検索)とベクトル検索を組み合わせることで、両方の長所を活用します。
BM25とベクトル検索の特性理解
- BM25の強み: 固有名詞、専門用語、正確な文字列マッチに優秀
- ベクトル検索の強み: 同義語、類似概念、意味的関連性の検出
- 組み合わせ効果: 精度と再現率の両方を向上
重み付け戦略
一般的にはベクトル検索に70%、BM25に30%の重みを割り当てることが多いですが、ドメインや用途によって調整が必要です。技術文書では固有名詞が重要なためBM25の重みを上げ、一般文書では意味的類似性が重要なためベクトル検索の重みを上げます。
スコア正規化の重要性
異なる検索手法のスコアを統合する際は、適切な正規化処理が必要です。各検索結果のスコア分布を分析し、最小最大正規化やZ-scoreの正規化を適用してから統合します。
埋め込みモデルの選択・チューニング
埋め込みモデル(文章を数値に変換して意味を理解できるようにするモデル)を、あなたの用途に合わせて最適化するうさ🐰
使う分野(技術文書、法務文書、一般文書など)によって、最適な埋め込みモデルが異なります。適切なモデルを選ぶことで検索精度が大きく変わります。
用途に応じた最適な埋め込みモデルの選択が検索精度に大きく影響します。
主要モデルの特性比較
- BGE-M3: 多言語対応、日本語の文脈理解に優秀、汎用性高い
- text-embedding-ada-002: OpenAI製、英語に強い、API経由で簡単利用
- Sentence-BERT: オープンソース、カスタマイズ性高い、計算リソース要
- E5-large-v2: Microsoft製、英語圏の技術文書に特化
ドメイン特化チューニングの手順
- データセット準備: ドメイン固有の文書ペア(類似/非類似)を作成
- ファインチューニング実行: コントラスティブ学習で類似性を学習
- 検証と調整: テストセットで性能評価し、パラメータ調整
- 本番適用: 段階的にロールアウトして効果測定
リランキング手法の導入
最初の検索結果をもう一度詳しく見直して、本当に関連性の高い情報だけを選び出すうさ🐰
初回の検索では候補が多すぎて、中には関連性の低い情報も含まれます。リランキングで精度の高い情報だけを厳選することで、AIの回答品質が向上します。
検索結果をより精緻に順序付けして、関連性の高い情報を優先的に選択します。
Cross-Encoderによるリランキング
初期検索で得られた候補文書を、クエリとの関連度でより詳細に評価し直します。計算コストは高いですが、精度向上効果は大きいです。
段階的リランキング戦略
- 第1段階: 高速な検索で候補を100件程度に絞り込み
- 第2段階: Cross-Encoderで上位20件を精密評価
- 第3段階: ビジネスルールで最終的に5〜10件を選択
多様性の確保
同じ文書や類似内容ばかりが選ばれることを防ぐため、Maximum Marginal Relevance(MMR)などの手法で多様性を確保します。
【3】 生成品質の向上
戦略的プロンプトエンジニアリング
AIに「どんな風に答えてほしいか」を具体的に指示することで、回答の質を向上させるうさ🐰
AIは指示が曖昧だと、期待と違う答えを返したり、根拠のない推測をしたりします。明確な指示により、正確で有用な回答を得られます。
検索結果を生成AIに渡す際のプロンプト設計が、回答品質に直結します。
構造化プロンプトの設計
- 役割定義: AIの専門性と責任範囲を明確化
- 回答ルール: 情報の扱い方、推測の禁止、出典の義務化
- 参考情報: 検索結果を整理して提示
- 質問: ユーザーの質問を明確に提示
- 回答形式: 期待する回答の構造と形式を指定
📝 すぐに使える!プロンプトテンプレート集
ここでは、実際にコピペして使える具体的なプロンプト例を、GOOD/BADパターンで紹介します。
🚫 BADプロンプト例
以下の情報を使って質問に答えて。
【参考情報】
{検索結果}
【質問】
{ユーザーの質問}問題点
- 役割や責任が不明確
- 情報の使い方の指示がない
- 推測や創作を防ぐルールがない
- 出典の明記ルールがない
✅ GOODプロンプト例
# 役割
あなたは正確性を重視する企業向けAIアシスタントです。
# 回答ルール
- 提供された参考情報のみを使用してください
- 参考情報にない内容は推測せず、「情報がありません」と明記してください
- 回答には必ず出典(文書名や段落番号)を含めてください
- 不確実な表現(「〜かもしれません」)は避け、事実ベースで回答してください
# 参考情報
---
{検索結果}
---
# 質問
{ユーザーの質問}
# 回答形式
- 簡潔な要約から開始
- 詳細な説明
- 出典の明記🎯 用途別プロンプトテンプレート
1. 技術文書向けプロンプト
# 役割
あなたは技術的精度を最優先する開発者向けサポートAIです。
# 回答ルール
- コードや設定は参考情報から正確に引用してください
- 技術的な推測は一切行わず、不明な点は明確に指摘してください
- 複数の方法がある場合は、すべての選択肢を提示してください
- セキュリティに関わる内容は特に慎重に扱ってください
# 参考情報
---
{検索結果}
---
# 質問
{ユーザーの質問}
# 期待する回答形式
1. 結論(1-2行)
2. 具体的な手順(必要に応じてコード例を含む)
3. 注意事項やベストプラクティス
4. 出典2. ビジネス文書向けプロンプト
# 役割
あなたは正確性と実用性を両立するビジネスサポートAIです。
# 回答ルール
- 参考情報の内容を正確に伝えつつ、実用的なアドバイスを提供してください
- 法務や規制に関わる内容は、必ず最新性の確認を促してください
- 複雑な内容は、分かりやすく構造化して説明してください
- 実行可能な次のステップを含めてください
# 参考情報
---
{検索結果}
---
# 質問
{ユーザーの質問}
# 期待する回答形式
## 概要
(重要なポイントを3行以内で)
## 詳細
(具体的な内容)
## 次のステップ
(実行可能なアクション)
## 出典
(参考にした文書)3. FAQ対応向けプロンプト
# 役割
あなたは顧客対応の品質向上を目指すサポートAIです。
# 回答ルール
- 参考情報をもとに、親しみやすく正確な回答をしてください
- よくある誤解がある場合は、それも含めて説明してください
- 追加で確認が必要な場合は、具体的に指示してください
- 緊急性が高い内容の場合は、優先度を明記してください
# 参考情報
---
{検索結果}
---
# 質問
{ユーザーの質問}
# 期待する回答形式
簡潔で分かりやすい回答(親しみやすい語調で)
必要に応じて補足や注意事項
出典と確認先プロンプト品質チェックリスト
RAGプロンプトの品質を確保するために、以下のリストを活用してください。
✅ 基本要素のチェック
- [ ] AIの役割が明確に定義されている
- [ ] 参考情報の使用ルールが明記されている
- [ ] 推測や創作を禁止するルールがある
- [ ] 出典明記の指示がある
- [ ] 回答形式が具体的に指定されている
✅ 精度向上のためのチェック
- [ ] 情報不足時の対応が明記されている
- [ ] 不確実性の表現ルールがある
- [ ] 複数選択肢がある場合の対応が指示されている
- [ ] セキュリティや法務に関する注意事項がある
✅ ユーザビリティのチェック
- [ ] 回答の構造が分かりやすい
- [ ] 実用的なアドバイスを含むよう指示している
- [ ] 次のステップが明確になっている
- [ ] 語調や親しみやすさが適切に設定されている
コンテキスト最適化
検索結果をそのまま渡すのではなく、関連度順に並べ替え、重複を除去し、文字数制限内に収まるよう調整します。
出力制御・後処理の最適化
AIが生成した回答をさらにチェックして、品質を向上させる仕組みうさ🐰
AIは時々事実と異なることを言ったり、読みにくい文章を作ったりします。後処理で自動的にチェック・修正することで、より信頼性の高い回答になります。
生成された回答を更に改善するための後処理を実装します。
事実整合性チェック
生成された回答が参考情報と矛盾していないかを自動的にチェックし、一貫性スコアが低い場合は不確実性を示すマーカーを追加します。
引用の自動生成
回答中の各主張に対して、参考情報のどの部分から得られた情報かを自動的に関連付けて引用を生成します。
可読性向上処理
- 文章構造の改善: 長すぎる文の分割、適切な段落分け
- 専門用語の説明: 必要に応じて用語の補足説明を追加
- 視覚的構造化: 重要なポイントの箇条書き化
【4】 評価・監視システムの構築
包括的評価指標の設定
RAGシステムがちゃんと動いているかを数値で測定する仕組みうさ🐰
「なんとなく調子が良い・悪い」ではなく、具体的な数値で性能を把握することで、どこを改善すべきかが明確になります。
RAGシステムの性能を多角的に評価するための指標体系を構築します。
検索精度の評価指標
- Precision(適合率): 検索結果のうち関連性のある文書の割合
- Recall(再現率): 関連性のある全文書のうち検索できた割合
- MRR(平均逆順位): 最初の正解が現れる順位の逆数の平均
- NDCG: 順位を考慮した評価指標
生成品質の評価指標
- Faithfulness(忠実性): 生成された回答が参考情報に基づいているか
- Answer Relevancy(回答関連性): 回答がユーザーの質問に適切に対応しているか
- Context Precision(文脈精度): 提供されたコンテキストの関連性
- Context Recall(文脈再現率): 必要な情報がコンテキストに含まれているか
システム性能の評価指標
- Response Time(応答時間): エンドツーエンドの処理時間
- Throughput(処理量): 単位時間あたりの処理可能クエリ数
- Cost per Query(クエリ単価): 1回の処理にかかるコスト
評価フレームワークの活用
RAGASやRAGCheckerなどの専用評価ツールを活用して、自動化された継続的な品質評価を実現します。
継続的監視・アラートシステム
RAGシステムの調子が悪くなったら自動的に教えてくれる仕組みうさ🐰
システムの性能は時間とともに劣化することがあります。問題を早期発見して対処することで、ユーザーに悪い体験をさせることを防げます。
本番運用での品質維持のための監視体制を構築します。
性能劣化の早期検出
- 精度閾値監視: 忠実性スコアが設定値を下回った場合のアラート
- レスポンス時間監視: 応答時間の異常な増加を検出
- エラー率監視: 失敗率の上昇をリアルタイムで検知
データドリフトの検出
時間経過とともにデータの特性が変化することで性能が劣化する現象を監視し、再トレーニングや調整の必要性を判断します。
ユーザーフィードバックの収集
- 明示的フィードバック: いいね/だめボタン、5段階評価
- 暗黙的フィードバック: クリック率、滞在時間、再検索率
- フィードバック分析: 収集したデータからパターンを抽出し改善に活用
【5】 実装時の落とし穴と対策
よくある問題とソリューション
実際のRAG導入で頻発する問題とその解決策を紹介します。
問題1: 検索結果の関連性が低い
原因分析
- クエリの意図理解不足
- 文書の前処理不備
- 埋め込みモデルとドメインのミスマッチ
解決策
- クエリ拡張: 同義語辞書や関連語を活用したクエリの自動拡張
- 専門用語補完: ドメイン知識を活用した用語の自動補完
- 意図分類: クエリの種類(事実確認、手順説明、比較など)を分類し、それに応じた検索戦略を適用
問題2: レスポンス速度の遅延
原因分析
- 大量文書の線形検索
- 重複した計算処理
- 不適切なインデックス設計
解決策
- 階層キャッシング: クエリレベル、埋め込みレベル、結果レベルの多段キャッシュ
- インデックス最適化: HNSWアルゴリズムによる近似最近傍検索の活用
- 並列処理: 検索と生成の並列実行、バッチ処理の導入
問題3: ハルシネーションの残存
原因分析
- 不十分なコンテキスト情報
- 生成モデルの過度な創造性
- 事実検証機能の不備
解決策
- 多段階検証: 文脈整合性、事実検証、外部ソース確認の3段階チェック
- 保守的生成: 情報が不十分な場合の明示的な回答回避
- 信頼度スコア: 各回答に信頼度を付与し、低信頼度の場合は警告表示
【6】 セキュリティ・運用考慮事項
データ保護・アクセス制御
誰がどの情報にアクセスできるかを適切に管理する仕組みうさ🐰
企業の機密情報が適切に保護されないと、情報漏洩のリスクがあります。ユーザーの権限に応じて、アクセス可能な情報を制限することが重要です。
企業環境でのRAG運用では、セキュリティが最重要課題となります。
ロールベースアクセス制御
ユーザーの役職や部署に応じて、アクセス可能な文書を制限します。役員は全社情報にアクセス可能、一般職員は所属部署の情報のみアクセス可能といった階層的な制御を実装します。
データ分類とラベリング
- 機密度レベル: 公開/社内限定/機密/極秘の4段階分類
- 部署固有性: 特定部署のみがアクセス可能な情報の管理
- 時限性: 一定期間後にアクセス制限が発生する情報の管理
クエリサニタイゼーション
悪意のあるクエリやインジェクション攻撃を防ぐため、入力されるクエリの内容を検証し、危険なパターンを検出・除去します。
動的フィルタリング
ユーザーの権限に基づいて、検索対象となる文書を動的に絞り込みます。同じクエリでも、ユーザーによって異なる結果を返すことで、情報の適切な保護を実現します。
ログ・監査システム
誰がいつ何にアクセスしたかを記録する仕組みうさ🐰
万が一問題が発生した時に、原因を調査できるようにログを残しておくことで、セキュリティインシデントの対応や改善に役立ちます。
コンプライアンス要件を満たすための包括的なログ管理を実装します。
包括的ログ記録
- クエリログ: 誰が、いつ、何を検索したかの記録(機密性に配慮したハッシュ化)
- アクセスログ: どの文書にアクセスしたかの詳細記録
- システムログ: 性能指標、エラー情報、システム状態の記録
監査トレイルの構築
情報へのアクセス経路を完全に追跡可能にし、セキュリティインシデント発生時の原因究明を支援します。
プライバシー保護
個人情報を含むクエリや結果の取り扱いに特別な配慮を行い、必要に応じて仮名化や暗号化を実施します。
【7】 継続改善のPDCAサイクル
一度作って終わりではなく、継続的に改善し続ける仕組みうさ🐰
RAGシステムは使い続けるうちに、データが増えたり、ユーザーのニーズが変わったりします。定期的に見直して改善することで、常に最適な性能を保てます。
Plan(計画)- 戦略的改善計画の策定
評価指標とターゲット値の設定
現状のベースライン測定を行い、具体的で測定可能な改善目標を設定します。例えば「忠実性スコアを6ヶ月で0.85から0.90に向上」といった明確な目標を定めます。
A/Bテスト計画の策定
改善施策の効果を科学的に検証するため、統計的に有意な結果が得られるサンプルサイズとテスト期間を計算し、綿密なA/Bテスト計画を策定します。
改善仮説の立案
現状の問題分析に基づいて、「チャンクサイズを512から256に変更することで技術文書の検索精度が向上する」といった検証可能な仮説を立案します。
Do(実行)- 段階的改善の実施
段階的な機能改善
リスクを最小化するため、改善施策を段階的にロールアウトします。まず小規模なユーザーグループで検証し、問題がないことを確認してから全体に展開します。
パラメータ調整の体系的実験
複数のパラメータを同時に変更せず、一つずつ体系的に調整して効果を測定します。これにより、どの変更が効果的だったかを正確に把握できます。
ユーザーフィードバックの積極的収集
定量的な指標だけでなく、実際のユーザーからの質的なフィードバックも重視し、使いやすさや満足度の観点からも改善を図ります。
Check(評価)- 多角的効果測定
定量的・定性的な効果測定
設定した指標に基づく数値的な評価に加えて、ユーザーインタビューや利用状況の観察による定性的な評価も実施します。
統計的有意性の検証
A/Bテストの結果について、適切な統計検定を行い、観察された改善が偶然ではないことを確認します。
副作用の監視
意図した改善が得られた場合でも、他の指標に悪影響がないかを総合的に評価します。
Act(改善)- 継続的最適化
成功要因の水平展開
効果的だった改善施策を他の部分にも適用し、システム全体の性能向上を図ります。
失敗要因の根本分析
期待した効果が得られなかった場合は、根本原因を分析し、次回の改善計画に反映します。
長期的戦略の見直し
短期的な改善結果を踏まえて、中長期的な技術戦略やシステム設計の見直しを行います。
まとめ:実践的RAGシステムの構築に向けて
RAGシステムの精度向上は、システム全体の最適化と継続的な改善によって実現されます。
🎯 成功のためのキーポイント
技術面
- データ品質が最重要: システム全体の性能はデータの質で決まります
- ハイブリッドアプローチ: 複数の手法を組み合わせて相互補完を図る
- 段階的最適化: 一度に全てを変更せず、効果を確認しながら改善
- 包括的評価: 単一指標ではなく多角的な評価で全体最適を図る
運用面
- セキュリティファースト: 設計段階からプライバシーとセキュリティを考慮
- ユーザー中心設計: 技術的優秀さより実用性と使いやすさを重視
- チーム体制整備: 技術者だけでなく業務ユーザーも巻き込んだ改善体制
- 継続的学習: 失敗を恐れず実験と学習を繰り返す文化の醸成
🚀 次世代RAG技術への展望
2025年注目のトレンド
- GraphRAG: エンティティ関係を活用した構造化知識検索
- Agentic RAG: 動的な検索戦略を自律的に決定するAIエージェント
- Multimodal RAG: テキスト・画像・音声・動画を統合した総合検索
- Federated RAG: 複数組織間での安全な知識共有システム
実装の心構え
RAGは「完璧なシステムを一度で構築する」技術ではありません。むしろ「継続的に改善し続ける」ことで真価を発揮します。最初は小さく始めて、ユーザーフィードバックと定量的評価に基づいて着実に改善していくことが成功の鍵です。
また、技術的な完璧さを追求するあまり、実際のビジネス価値や使いやすさを見失わないよう注意が必要です。「技術的に興味深い」ことと「実用的に価値がある」ことは必ずしも一致しません。
🔄 実践への第一歩
この記事で紹介した手法を明日から実践するために、以下のステップから始めることをお勧めします
- 現状の定量的評価: まず現在のシステムの性能を正確に測定
- 優先順位の決定: 最もインパクトの大きい改善ポイントを特定
- 小規模実験: リスクの低い改善から着手して経験を積む
- 成果の共有: チーム内で学習内容と成果を共有して知見を蓄積
RAGは生成AIを「知識に基づく専門家システム」へと進化させる重要な技術です。この記事で紹介した実践的手法を活用して、ビジネス価値の高いRAGシステムを構築してください。
継続的な改善と最新技術のキャッチアップにより、より高度で信頼性の高いAIシステムの実現を目指しましょう!🐰
あなたも生成AIの活用、始めてみませんか?
生成AIやRAGを使った業務効率化を、今すぐ始めるなら
「初月基本料0円」「ユーザ数無制限」のナレフルチャット!
生成AIの利用方法を学べる「公式動画」や、「プロンプトの自動生成機能」を使えば
知識ゼロの状態からでも、スムーズに生成AIの活用を始められます。
参考資料
taku_sid
https://x.com/taku_sid
AIエージェントマネジメント事務所「r488it」を創立し、うさぎエージェントをはじめとする新世代のタレントマネジメント事業を展開。AI技術とクリエイティブ表現の新たな可能性を探求しながら、次世代のエンターテインメント産業の構築に取り組んでいます。
ブログでは一つのテーマから多角的な視点を展開し、読者に新しい発見と気づきを提供するアプローチで、テックブログやコンテンツ制作に取り組んでいます。「知りたい」という人間の本能的な衝動を大切にし、技術の進歩を身近で親しみやすいものとして伝えることをミッションとしています。




スマートフォンでもAI活用!
アプリ版「ナレフルチャット」配信中
iPhoneはこちら


Androidはこちら




