PLUS
生成AIコラム
うさぎでもわかる! Embeddingモデル – Gemini Embedding 2と日本語最強OSS

目次:
はじめに
「気づけばまた新しいEmbeddingモデルが出てる…結局2026年春の正解は何?」
そう思って来てくれたあなた、ようこそうさ🐰
ここ半年でEmbedding界の景色は2つの動きで大きく変わりました。Gemini Embedding 2 Preview(2026年3月10日リリース)が、テキスト・画像・音声・動画・PDFを共通のベクトル空間に統合するマルチモーダルEmbeddingとして登場。同時に日本語OSS(Ruri v3、PLaMo-Embedding-1B、Sarashina-Embedding)がJMTEB上位を塗り替え、「日本語ではOSSがAPIを上回る」 という珍しい構図になりました。
つまりいまは、「グローバル指標だけで選ぶとハマる」 時代うさ。
生成AIの社内利用をお考えの企業様へ
ナレフルチャットは、初心者でも使いやすい設計で、RAGを活用した社内ナレッジ活用をスムーズに進められる法人向け生成AIツールです。社内マニュアルや業務資料をもとに回答できるため、AIリテラシーに差があっても、組織全体で実用的に活用できます。企業のAI導入を検討している方は、こちらをご覧ください。Embeddingってそもそも何? 3分で復習
データを「意味のベクトル」に翻訳する、検索AIの心臓部うさ🐰
Embeddingは、文章や画像などのデータを 数百〜数千次元の数値ベクトルへ変換する技術。意味が近いものほどベクトル空間でも近くに配置されるため、コサイン類似度のようなシンプルな計算で「意味検索」「類似検索」が成立します。「猫が好き」と「犬が好き」はご近所さん、「確定申告の方法」は遠くの街、というイメージうさ。この 「意味の地図」 が、RAG・セマンティック検索・レコメンド・クラスタリングのほぼすべてを支えています。
2026年、Embeddingの新潮流
2024年までは「テキスト専用+固定次元」が普通でしたが、2026年の最新モデルは様変わり。共通する3つのキーワードを押さえましょう。
- ネイティブ・マルチモーダル化 … テキストと画像を別モデルで扱う時代は終了。ひとつのモデルで統一空間へ
- Matryoshka Representation Learning(MRL) … ロシアの入れ子人形のように、大きなベクトルの先頭を切り取るだけで小さな次元として使える ように学習させる手法。1回の推論で得た3,072次元ベクトルを、用途に応じて128 / 768 / 1,536次元と自在に切り詰められるので「粗く絞って細かく見る」段階検索やストレージ最適化が一気に楽になります
- タスク指示の埋め込み(Task Instructions) … 同じ文でも「これはクエリ?文書?分類用?」をモデルに伝えてから埋め込む仕組み。
RETRIEVAL_QUERY/RETRIEVAL_DOCUMENTのようにタスク種別を渡すと、用途に最適化されたベクトルが返ってきて検索精度が底上げされます
そして、この3つを全部盛りにした2026年の最新モデルが、次章のGemini Embedding 2うさ🐰
Gemini Embedding 2 Preview 徹底解剖
2026年3月10日、Googleが投下した「マルチモーダル時代の決定版」うさ🐰
スペック早見表
前世代 gemini-embedding-001(テキスト専用)からアーキテクチャを刷新し、Geminiファミリーのマルチモーダル能力をEmbeddingに統合。「1モデルで全部やりたい」を叶えにきた一手です。
| 項目 | gemini-embedding-2-preview |
|---|---|
| 入力モダリティ | テキスト / 画像 / 音声 / 動画 / PDF |
| 入力トークン上限 | 8,192(前世代は2,048) |
| 出力次元 | 128〜3,072(MRL対応、推奨 768 / 1,536 / 3,072) |
| 対応言語 | 100以上(評価は250以上) |
| 価格(テキスト) | $0.20 / 1Mトークン(バッチは半額の$0.10) |
| 画像 / 音声 / 動画 | $0.45 / $6.50 / $12.00 per 1M(バッチ50%オフ) |
出典 Gemini Embedding 2 model / Gemini Developer API Pricing / Vertex AI Embedding 2 ドキュメント
ここがすごい、4つのポイント
- ネイティブ・マルチモーダル … テキスト・画像・音声・動画を 最初から同じ空間 にマッピング。「画像で探して、テキストで検索する」が1モデルで完結
- 発表時はMTEB Multilingualをはじめ複数部門でトップクラスのスコアを獲得 … その後 Llama-Embed-Nemotron-8B・Qwen3-Embedding-8B・Ruri v3 などのOSS新興モデルに追い抜かれてはいるものの、汎用Embeddingとしての完成度はいまもトップ層
- クロスリンガル検索が驚くほど強い … 英語クエリで日本語文書を引き当てるような言語をまたぐ検索でも、ヒット品質がほぼ落ちない
- Matryoshka対応で運用が柔らかい … 1回の推論で得たベクトルを用途に応じて自在にカット。「評価は高次元、本番は軽量な次元」といった切り替えが思いのまま
出典 Gemini Embedding 2 公式アナウンス / Best Embedding Model for RAG 2026 – Milvus Blog / Gemini Embedding 論文 arXiv 2503.07891
タスク指示(task_type)で精度を底上げする
Gemini Embeddingで地味に効くのが task_type パラメータ うさ🐰 同じテキストでも「クエリとして埋め込みたいのか、文書として埋め込みたいのか」をモデルに伝えられるので、検索精度がぐっと上がります。
主に使うのはこの5種類。
| task_type | 用途 |
|---|---|
RETRIEVAL_QUERY | RAGの クエリ側 を埋め込むとき |
RETRIEVAL_DOCUMENT | RAGの 文書側 を埋め込むとき |
SEMANTIC_SIMILARITY | 文章ペアの類似度判定 |
CLASSIFICATION / CLUSTERING | 分類・クラスタリング用途 |
CODE_RETRIEVAL_QUERY | 自然言語クエリでコードを探す |
ポイントは クエリと文書で task_type を使い分けること。両方を RETRIEVAL_DOCUMENT で埋め込んでしまうと、Gemini Embedding本来の精度を引き出せません。OpenAIの text-embedding-3-large には task_type の概念がないので、ここはGemini系の地味な強みうさ。
出典 Gemini API Embeddings ドキュメント / Gemini Embedding 論文 arXiv 2503.07891
前世代との差分とコストの落とし穴
| 項目 | gemini-embedding-001 | gemini-embedding-2-preview |
|---|---|---|
| モダリティ | テキストのみ | テキスト + 画像 + 音声 + 動画 + PDF |
| 入力トークン | 2,048 | 8,192 |
| 価格(テキスト) | $0.15 / 1M | $0.20 / 1M |
テキスト単価は33%アップですが、バッチ処理は半額なのでインデックス構築はバッチ一択。
注意したいのは音声・動画のコスト感。トークン換算するとかなり高くつくので、「社内データ全部ベクトル化」みたいな乱暴な使い方は財布が泣きます。テキスト+PDFから始めて、音声・動画は本当に必要な箇所だけに絞るのが現実解うさ🐰
出典 Gemini Embedding now generally available(Google Developers Blog) / TokenCost、Gemini Embedding 2 価格分析
法人向け生成AIサービス「ナレフルチャット」では、社内マニュアルや業務資料をもとに回答できるRAG機能を活用し、企業独自の情報に基づいた生成AI運用が可能です。一般的な生成AIでは難しい、社内情報を踏まえた回答や情報検索を実現し、問い合わせ対応や業務効率化を支援します。
また、料金プランは企業単位の定額制を採用しており、何人で利用しても追加コストは発生しないため、コスト管理の手間なくスムーズな全社導入を実現できます。
初月無料で生成AIが利用できるトライアル期間も用意しておりますので、生成AIの利活用を検討している企業様は、是非一度導入をご検討ください。実際に触って検証してみる
スコアより「なるほど、こうなるのか」を体感する3つのミニデモうさ🐰
ここでは厳密なベンチマークではなく、Gemini Embedding 2ならではの3つの特徴 「マルチモーダル」「MRL」「Task Instructions」 を、最小データで体感するデモを用意します。それぞれ 準備するデータ → やること → 見えるはずのこと の流れで紹介。
共通の呼び出しパターン
テキスト・画像・音声どれも同じAPIで埋め込めます。
from google import genai
client = genai.Client()
def embed(content, task_type="RETRIEVAL_DOCUMENT", dim=768):
return client.models.embed_content(
model="gemini-embedding-2-preview",
contents=content,
config={"task_type": task_type, "output_dimensionality": dim},
).embeddings[0].values
これで、テキストでも画像バイトでも音声バイトでも embed() 一発 で768次元ベクトルが返ってきますうさ。
デモ① 画像とテキストが同じベクトル空間にいる
マルチモーダル統合の感動ポイント。テキストクエリで画像が引ける のを目視確認うさ🐰
用意するデータ
- 画像3枚 …
cat.jpg(猫の写真)/dog.jpg(犬の写真)/car.jpg(車の写真) - テキストクエリ3つ …
"窓辺の猫"/"芝生で遊ぶ犬"/"青いスポーツカー"

やること
3枚の画像を埋め込み、3つのクエリそれぞれと最も近い画像を引いてくる。さらに768次元のベクトルをPCAで3次元に圧縮し、テキストと画像が空間内でどう配置されるかを可視化する。検証スクリプトは demo1_image_text.py にまとめてあるので、API キーと画像3枚を準備して実行するだけで結果が出ます。
実際の結果
[窓辺の猫]
cat.jpg cosine=0.3959 ← top-1
dog.jpg cosine=0.2803
car.jpg cosine=0.2587
[芝生で遊ぶ犬]
dog.jpg cosine=0.4002 ← top-1
cat.jpg cosine=0.2843
car.jpg cosine=0.2150
[青いスポーツカー]
car.jpg cosine=0.3481 ← top-1
dog.jpg cosine=0.2514
cat.jpg cosine=0.2419
3クエリすべてで正解画像がtop-1に来ました。コサイン類似度をマトリクスにすると、対角線が一番濃く光るのが一目でわかります。
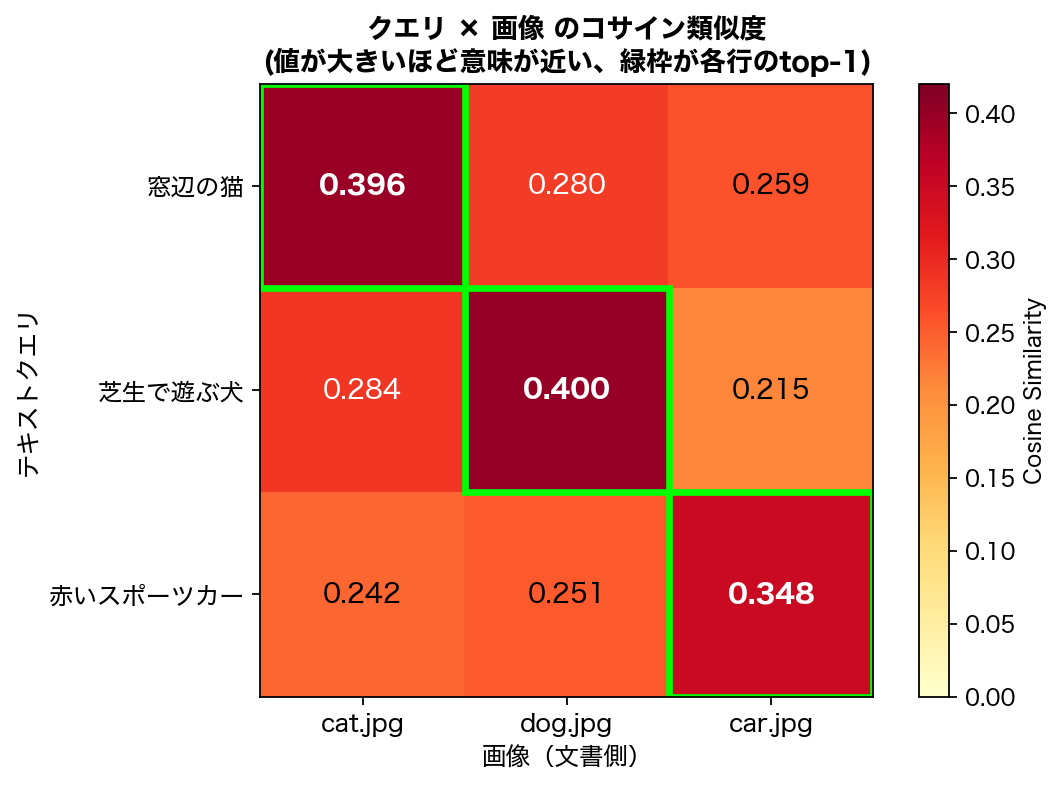
出典 検証コードの実行結果(クエリ × 画像 のコサイン類似度マトリクス)
ここからわかること
- 正解とそれ以外の差は約0.10〜0.15。決定的な大差ではないものの、ランキングは安定して正解
- コサイン類似度の絶対値は0.3〜0.4と控えめ。これは クロスモーダル(テキスト × 画像)の埋め込みは同モーダル同士よりスコアが小さく出る という Gemini Embedding 2 の特性
デモ② MRLで「1回の推論を切るだけ」で次元を変える
「ベクトルを切るだけで小さくできる」を実感するデモうさ🐰
用意するデータ
- デモ①と同じ …
cat.jpg/dog.jpg/car.jpg+ クエリ"窓辺の猫"/"芝生で遊ぶ犬"/"青いスポーツカー"
やること
3,072次元で1回だけ埋め込んだベクトル をローカルで先頭 N 次元に切って L2 正規化し直し、コサイン類似度ランキングを比較。検証スクリプトは demo2_mrl.py にまとめてあります。API呼び出しは コンテンツ数(6回)のみ で、128 / 768 / 3,072 のすべての検証を済ませている点がポイント。
def slice_and_renorm(vec: np.ndarray, dim: int) -> np.ndarray:
sliced = vec[:dim]
return sliced / np.linalg.norm(sliced)
実際の結果
=== 3,072次元で1回だけ埋め込み(API呼び出しは 6 回のみ)===
--- 次元 128(先頭128次元を切り出してL2正規化)---
[窓辺の猫] cat(0.297) > dog(0.251) > car(0.247)
[芝生で遊ぶ犬] dog(0.341) > cat(0.227) > car(0.220)
[青いスポーツカー] car(0.335) > dog(0.151) > cat(0.148)
--- 次元 768(先頭768次元を切り出してL2正規化)---
[窓辺の猫] cat(0.396) > dog(0.280) > car(0.259)
[芝生で遊ぶ犬] dog(0.400) > cat(0.284) > car(0.215)
[青いスポーツカー] car(0.348) > dog(0.251) > cat(0.242)
--- 次元 3072(先頭3072次元を切り出してL2正規化)---
[窓辺の猫] cat(0.373) > dog(0.260) > car(0.246)
[芝生で遊ぶ犬] dog(0.385) > cat(0.270) > car(0.201)
[青いスポーツカー] car(0.331) > dog(0.237) > cat(0.229)
[top-1の一貫性チェック] 全クエリOK
3次元すべてで正解画像がtop-1を維持。ヒートマップで並べると、緑枠の位置(=各行のtop-1)が3枚とも同じ位置にあるのが一目でわかります。
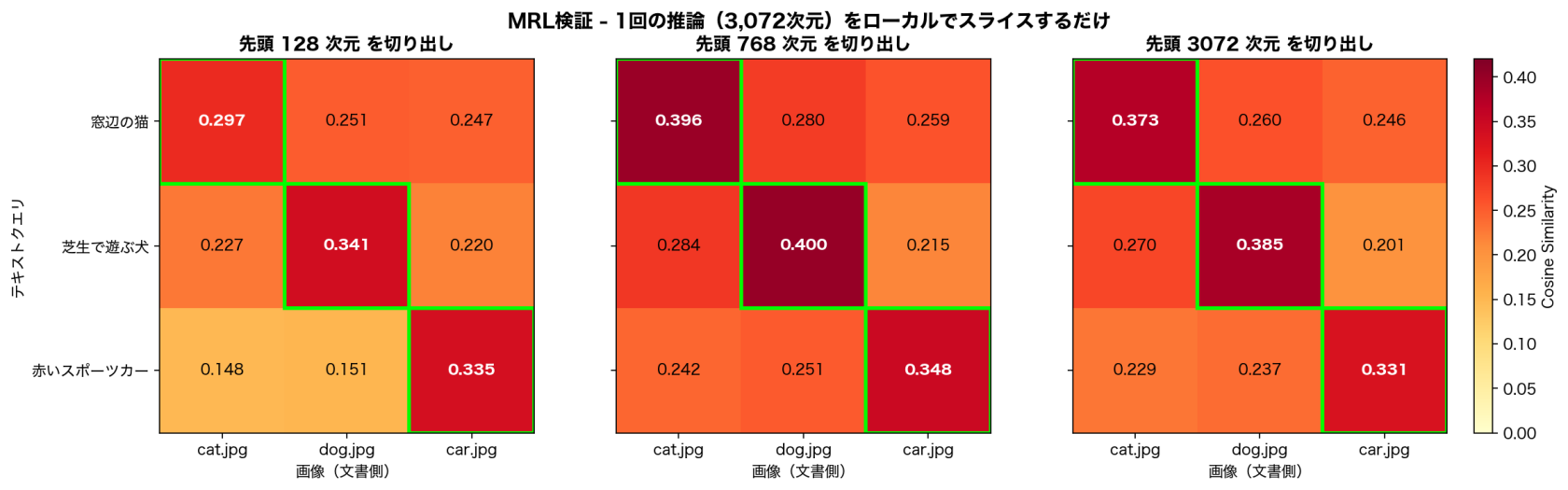
出典 検証コードの実行結果(3,072次元で1回だけ埋め込み → 先頭 128 / 768 / 3,072 次元を切り出して比較)
ここからわかること
- API呼び出しは1回で済む … 3,072次元で叩いた結果をローカルで切るだけで、128次元のランキングが手に入る。MRLの「評価は高次元、本番は軽量な次元」が実機で成立
- 次元を1/24に圧縮してもランキングは崩れない … これが MRL の実用性の核
- 絶対値は768次元がピーク … 128では値がやや下がり、3,072では逆にわずかに下がる。この検証では 768次元が「精度 × ストレージ」のスイートスポット という結果に
- 正解と次点の差は128次元でも約0.05残る … 値の絶対差は小さくなるものの、ランキングの安定性は確保
- ちなみに、APIで
output_dimensionality=128を指定した場合の結果と、3,072次元を切ってL2正規化した結果は 小数点3桁まで完全一致。つまり API側がやっているのも「先頭を切ってL2正規化」と同じ操作なので、手元で切るぶんには課金的にも完全に等価 … 実運用で 「インデックス全体は128次元で軽量に持ち、リランキング時だけ768次元を使う」 という段階検索が、追加コストなしで成立しますうさ🐰
デモ③ task_typeを変えると結果は動くのか
「タスク指示の埋め込み」がどれくらい効くのかを実測するデモうさ🐰
用意するデータ
- デモ①と同じ …
cat.jpg/dog.jpg/car.jpg+ クエリ"窓辺の猫"/"芝生で遊ぶ犬"/"青いスポーツカー"
やること
クエリと画像を 3パターンの task_type 組み合わせ で埋め込み、ランキングと「正解 – 次点」のコサイン差(マージン)を比較。検証スクリプトは demo3_task_type.py にまとめてあります。
| 設定 | クエリ側 | 画像側 |
|---|---|---|
| 正しい使い分け | RETRIEVAL_QUERY | RETRIEVAL_DOCUMENT |
| 雑に揃える | RETRIEVAL_DOCUMENT | RETRIEVAL_DOCUMENT |
| task_type無指定 | なし | なし |
実際の結果
--- 正しい使い分け ---
[窓辺の猫] cat(0.396) > dog(0.280) > car(0.259)
[芝生で遊ぶ犬] dog(0.400) > cat(0.284) > car(0.215)
[青いスポーツカー] car(0.348) > dog(0.251) > cat(0.242)
--- 雑に揃える ---
[窓辺の猫] cat(0.396) > dog(0.280) > car(0.259)
[芝生で遊ぶ犬] dog(0.400) > cat(0.284) > car(0.215)
[青いスポーツカー] car(0.348) > dog(0.251) > cat(0.242)
--- task_type無指定 ---
[窓辺の猫] cat(0.396) > dog(0.280) > car(0.259)
[芝生で遊ぶ犬] dog(0.400) > cat(0.284) > car(0.215)
[青いスポーツカー] car(0.348) > dog(0.251) > cat(0.242)
[マージン集計]
パターン top1正解率 平均マージン 最小マージン
正しい使い分け 100% +0.109 +0.097
雑に揃える 100% +0.109 +0.097
task_type無指定 100% +0.109 +0.097
3パターンとも完全に同じコサイン値が返ってきました。ヒートマップを並べても全く同じ模様で、緑枠の位置・色の濃淡まで一致します。
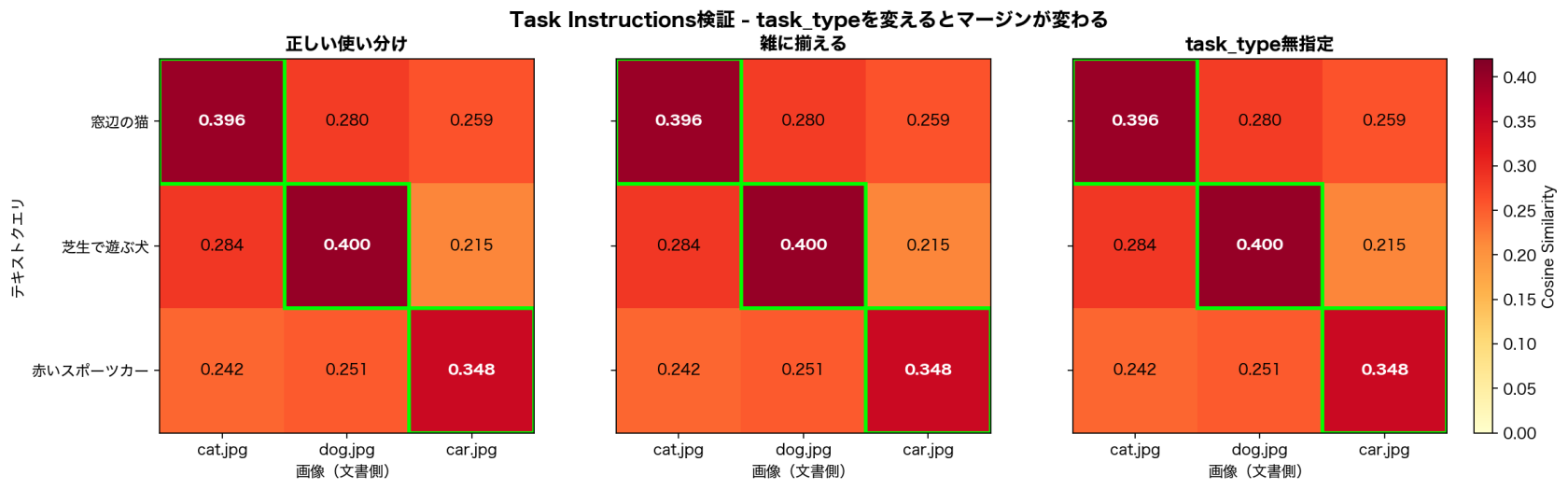
出典 検証コードの実行結果(task_type 3パターンの比較)
ここからわかること
- Preview段階の今の挙動 … 少なくとも今回のような小さな対称ケースでは、
task_typeを変えても、無指定にしても、出力ベクトルに差は観測されませんでした。Preview API 側でtask_typeがまだ実効的に効いていない可能性があります - 公式ドキュメントの推奨は変わらず … 仕様上は「クエリは
RETRIEVAL_QUERY、文書はRETRIEVAL_DOCUMENT、類似度比較はSEMANTIC_SIMILARITY」と分けるのが正解。GA時には差が出てくる前提でコード側は最初から正しく書いておくのが安全です - 本番規模では別の話になりそう … 3クエリ × 3画像という極小データだと差が見えなくても、数万件規模で「QA/類似検索/コード検索」が混ざる状況では
task_typeの効きが出やすいはず。ここは GA 後に再検証したいポイントうさ🐰
→ 結論として 「今は差が出なくても、コード側は task_type を正しく指定しておく」 が現実解です。Previewの今の挙動だけ見て省略すると、GAで挙動が変わった瞬間に検索品質が崩れる可能性があります。
2026春 Embeddingモデル選定ガイド
主要モデルの勢力図・日本語の現実・ユースケース別の最適解、まとめて見ていくうさ🐰
メジャーモデルマップ(2026年4月時点)
2026年は 「モダリティ × コンテキスト長 × 次元数 × ユースケース」の4軸 で選ぶ時代。グローバル視点の主要モデルを、ざっくり一覧化しました。
| モデル | 次元 | 最大トークン | 一言 |
|---|---|---|---|
| Gemini Embedding 2 Preview | 128〜3,072 | 8,192 | マルチモーダル対応、発表時はMTEB上位 |
| Gemini Embedding 001 | 最大3,072 | 2,048 | テキスト専用、いまもMTEB上位の安定枠 |
| OpenAI text-embedding-3-large | 3,072 | 8,191 | 安定の定番、クロスリンガルに強い |
| Qwen3-Embedding-8B | 4,096 | 32,000 | OSS多言語最強クラス、Apache 2.0 |
| multilingual-e5-large | 1,024 | 512 | 軽量・枯れた定番OSS |
スコア・価格・ライセンスは必ず公式リーダーボードで 確認してくださいうさ🐰
モデルは月単位で入れ替わるので、本記事に固定値を載せるよりも一次情報を見るほうが確実。
- 多言語スコア → MTEB Leaderboard(Hugging Face)
- 日本語スコア → JMTEB GitHub(評価スクリプト・最新情報)
日本語観点で見るJMTEBスコア
ここからが本記事のキモうさ🐰
日本語RAGを作るなら、MTEBの英語タブよりJMTEBで評価する のが鉄則。
JMTEB(Japanese Massive Text Embedding Benchmark) はSB Intuitionsが構築した日本語向けベンチマークで、Retrieval / STS / Classification / Reranking / Clustering / PairClassification を多面的に評価します。
確認方法はMTEB Leaderboardに統合済み で、専用ページは廃止されました。
- 表示先 … MTEB Leaderboard の General Purpose → Language-specific → Japanese タブ
- 評価スクリプト … JMTEB GitHub
- 構築の背景 … JMTEB 構築解説(SB Intuitions TECH BLOG)
そして見どころは現在の力関係。2025〜2026年にかけて日本語特化OSSが急増し、いまや 日本語ではOSSがAPIモデルを上回る 状況になっています。
具体的なスコアは月単位で更新されるので本記事には載せず、各モデル開発者と第三者検証の 一次情報 を案内します。
- Ruri v3 シリーズの詳細スコア → Ruri 日本語に特化した汎用テキスト埋め込みモデル(Zenn)
- PLaMo-Embedding-1Bの詳細スコア → PLaMo-Embedding-1B Tech Blog(Preferred Networks)
- 国内モデルの横断評価 → Embedding Gemma 300M JMTEB評価(A Day in the Life)
クロスリンガル検索(英語クエリ→日本語文書)はAPIが強い
「日本語ならOSS一択?」と思うかもしれませんが、ちょっと待ってうさ🐰
英語クエリで日本語文書を探すクロスリンガル検索 では、APIモデルが頭ひとつ抜ける傾向があります(oshizo氏の検証より)。
| モデル | クロスリンガルでの強み |
|---|---|
OpenAI text-embedding-3-large | 英訳による劣化が小さい |
Cohere embed-v4 | EN-JA / JA-JAの合計スコアが高く汎用性トップ |
ruri-v3 | 日本語内検索は圧倒的、クロスリンガルはやや苦手 |
つまり棲み分けはシンプル。英語と日本語が混在する環境はAPI、純日本語ならOSS が現実解うさ。
ユースケース別 2026春の使い分け
🇯🇵 日本語メインのRAG(社内ナレッジ検索など)
→ 第一候補は cl-nagoya/ruri-v3-310m(セルフホスト可)。GPUリソースが厳しいなら ruri-v3-30mでも十分。日本語性能でAPIより自前モデルが強い 珍しい分野なので、せっかくなら活用したいうさ。
🌏 マルチモーダル検索(画像・PDF・動画も含めたい)
→ 本命は Gemini Embedding 2 Preview 一択。「社内プレゼンPDFをまるごと意味検索」「動画の特定シーンをテキストで探す」にハマります。コスト重視なら Cohere embed-v4(PDF画像をOCRなしで扱える)も検討候補。
💰 大規模コーパス・低予算運用
→ コスパの王者は OpenAI text-embedding-3-small。日本語性能も悪くなく、プロトタイプや数百万文書規模のインデックス構築なら第一候補。精度が欲しくなったら text-embedding-3-large へ。
🔒 オンプレ必須・データ主権が必要
→ Ruri v3 シリーズ(Apache 2.0、30M〜310M)か Qwen3-Embedding-8B(Apache 2.0)。日本語メインならRuri、多言語ならQwen3。多言語の軽量構成なら BGE-M3(MIT、100言語以上)も有力。
まとめ – 2026年春のEmbedding選びで覚えてほしいこと
ここまで読んでくれて、本当にありがとうさ🐰
1. Gemini Embedding 2でマルチモーダル時代が本格到来
テキスト・画像・音声・動画・PDFをひとつのベクトル空間で扱えるのは、2026年時点で Gemini Embedding 2の独壇場。クロスモーダル検索を考えているなら、まず触っておく価値があります。
2. 日本語はグローバル指標と別軸で評価する
MTEBで高得点でも日本語ではガクッと落ちるモデルは珍しくありません(EmbeddingGemmaが好例)。日本語RAGを本気で作るならJMTEBで必ず再確認。Ruri v3・PLaMo-Embedding・Sarashina Embeddingといった国産モデルの存在感は本当に頼もしい限りうさ。
3. モデル選定は「モダリティ × 言語 × コスト × 主権」の4軸
MTEBスコア一本勝負の時代は終わりました。4軸のうち何を重視するかを言語化すること が、最良の選択への第一歩うさ。
大事なのは 「どのモデルが最強か」ではなく「自分のユースケースで最強は何か」。実データでちゃんと検証する文化を大切にしたいうさ。
お疲れさまでした!あなたのRAGや検索システムが、2026年仕様でさらに賢くなりますように🐰
あなたも生成AIの活用、始めてみませんか?
生成AIを使った業務効率化を、今すぐ始めるなら
「初月基本料0円」「ユーザ数無制限」のナレフルチャット!
生成AIの利用方法を学べる「公式動画」や、「プロンプトの自動生成機能」を使えば
知識ゼロの状態からでも、スムーズに生成AIの活用を始められます。
taku_sid
https://x.com/taku_sid
AIエージェントマネジメント事務所「r488it」を創立し、うさぎエージェントをはじめとする新世代のタレントマネジメント事業を展開。AI技術とクリエイティブ表現の新たな可能性を探求しながら、次世代のエンターテインメント産業の構築に取り組んでいます。
ブログでは一つのテーマから多角的な視点を展開し、読者に新しい発見と気づきを提供するアプローチで、テックブログやコンテンツ制作に取り組んでいます。「知りたい」という人間の本能的な衝動を大切にし、技術の進歩を身近で親しみやすいものとして伝えることをミッションとしています。








スマートフォンでもAI活用!
アプリ版「ナレフルチャット」配信中
iPhoneはこちら


Androidはこちら




