PLUS
生成AIコラム
うさぎでもわかるAI OCR完全ガイド

はじめに
「紙の書類をデジタル化したいけど、手入力は大変…」
そんな悩みを解決してくれるのがOCR技術です。OCRは昔からある技術ですが、最近はAIの力でとても賢くなりました。
この記事で学べること
- OCRの基本的な仕組み
- 従来OCRとAI OCRの違い
- マルチモーダルLLMによる次世代OCR
- DeepSeek OCR
それでは、OCRの基本から最新技術まで順番に見ていきましょう🐰
生成AIの社内利用をお考えの企業様へ
ナレフルチャットは組織全体への生成AI浸透を支援するツールです。既存のチャット機能はもちろん、画像や図形の読み取り、音声データやホワイトボードの写真から文章の書き起こしや要約まで、身近な業務から任せることができます。企業のAI導入を検討している方は、こちらをご覧ください。OCRとは何か
画像から文字を読み取る技術について、基本を押さえるうさ!
OCRは「Optical Character Recognition」の略で、日本語では「光学文字認識」と呼ばれます。
簡単に言うと、画像やスキャンした文書から文字を読み取って、テキストデータに変換する技術です。
OCRの処理の流れ
OCRは以下の3ステップで文字を認識します。
- 画像を取り込む – スキャナやカメラで紙の文書を画像として取り込みます
- 文字を認識する – 画像の中から文字を見つけて、何の文字か判別します
- テキストを出力する – 認識した文字をテキストデータとして出力します
身近なOCRの活用例
私たちの身の回りでも、OCRは様々な場面で活躍しています。
| 場面 | 使われ方 |
|---|---|
| 名刺管理アプリ | スマホで撮影するだけで連絡先を自動登録 |
| 経費精算 | レシートを撮影して金額・日付を自動入力 |
| PDF検索 | スキャンしたPDFの文字検索が可能に |
| 翻訳アプリ | カメラで写した外国語を即座に翻訳 |
紙に書かれた情報をデジタルデータとして活用できるようになるため、業務効率化に欠かせない技術となっています🐰
従来OCRとAI OCRの違い
どう進化したのか、比較しながら見ていくうさよ🐰
OCR技術は大きく進化しています。従来のOCRとAI OCRの違いを見てみましょう。
従来OCR
従来のOCRは「パターンマッチング」という方法で文字を認識します。あらかじめ登録された文字の形と、画像の文字を照合して判別する仕組みです。
得意なこと
- 印刷された綺麗な文字の認識
- 決まったフォーマットの文書処理
苦手なこと
- 手書き文字の認識
- 複雑なレイアウトの文書
- 斜めになった文字や汚れた文書
代表例として、Tesseract 3.x以前などが該当します。
AI OCR
AI OCRは「ディープラーニング(深層学習)」という技術を使います。大量のデータから文字のパターンを学習し、人間のように文字を認識できるようになりました。
AI OCRの強み
- 手書き文字も高精度で認識
- 複雑なレイアウトにも対応
- 文脈を理解して誤りを自動修正
代表例として、PaddleOCRなどが該当します。
従来OCRとAI OCRの精度比較
実際にどれくらい差があるのか、ベンチマーク結果を見てみましょう。
| 指標 | Tesseract(従来) | PaddleOCR(AI) |
|---|---|---|
| 文字エラー率(CER) | 0.182 | 0.045 |
| 単語精度 | 75.8% | 92.1% |
| 精度(単語レベル) | 81.0% | 94.5% |
| F1スコア(単語レベル) | 0.797 | 0.938 |
出典:Paddle OCR vs. Tesseract: A Comparative Performance Analysis
AI OCRは従来OCRと比べて、文字エラー率が約4分の1に減少していることがわかります。
実際の導入事例
AI OCRは様々な業界で業務効率化に貢献しています。
金融業界
銀行や証券会社では、本人確認書類や契約書の処理にAI OCRを導入しています。
物流業界
配送伝票や送り状の処理にAI OCRを活用し、入力作業の効率化を実現しています。
保険業界
保険金請求書や医療明細の読み取りに導入し、処理スピードを向上させています。
法人向け生成AIサービス「ナレフルチャット」なら、Gemini 3.1 Pro、Claude、GPT-5など最新のマルチモーダルLLMを自由に選んで利用でき、記事で検証したような高精度なOCRを実務レベルで活用できます。
さらに、ナレフルチャットはセキュアな環境で運用されているため、個人情報や機密データも安心して扱えます。企業単位の定額制料金プランにより、何人で利用しても追加コストは発生しないため、全社導入もスムーズです。マルチモーダルLLMによるOCR
画像と言語を同時に理解するAIの登場うさ!
最近注目されているのが「マルチモーダルLLM」を活用したOCRです。
マルチモーダルLLMとは、画像とテキストを同時に理解できるAIのこと。従来の「文字を読み取る」だけでなく、「文書の意味を理解する」ことができるようになりました。
何ができるようになったのか
文書構造の理解
表やグラフ、見出しと本文の関係など、文書全体の構造を把握できます。単に文字を読み取るだけでなく、「ここは表のヘッダー」「ここは注釈」といった意味まで理解します。
文脈による自動修正
「I1linois」を「Illinois」に自動修正するなど、文脈から正しい文字を推測できます。OCRの誤認識を大幅に減らせる画期的な機能です。
多言語対応
50以上の言語に対応し、複数の言語が混在した文書も処理できます。日本語と英語が混在するビジネス文書も問題なく処理可能です。
代表的なモデル
Gemini 3 Pro発表時のベンチマーク(OmniDocBench 1.5)でも示されているように、現在Gemini 3 Proがマルチモーダルモデルの中で最も良い認識精度を達成しています。
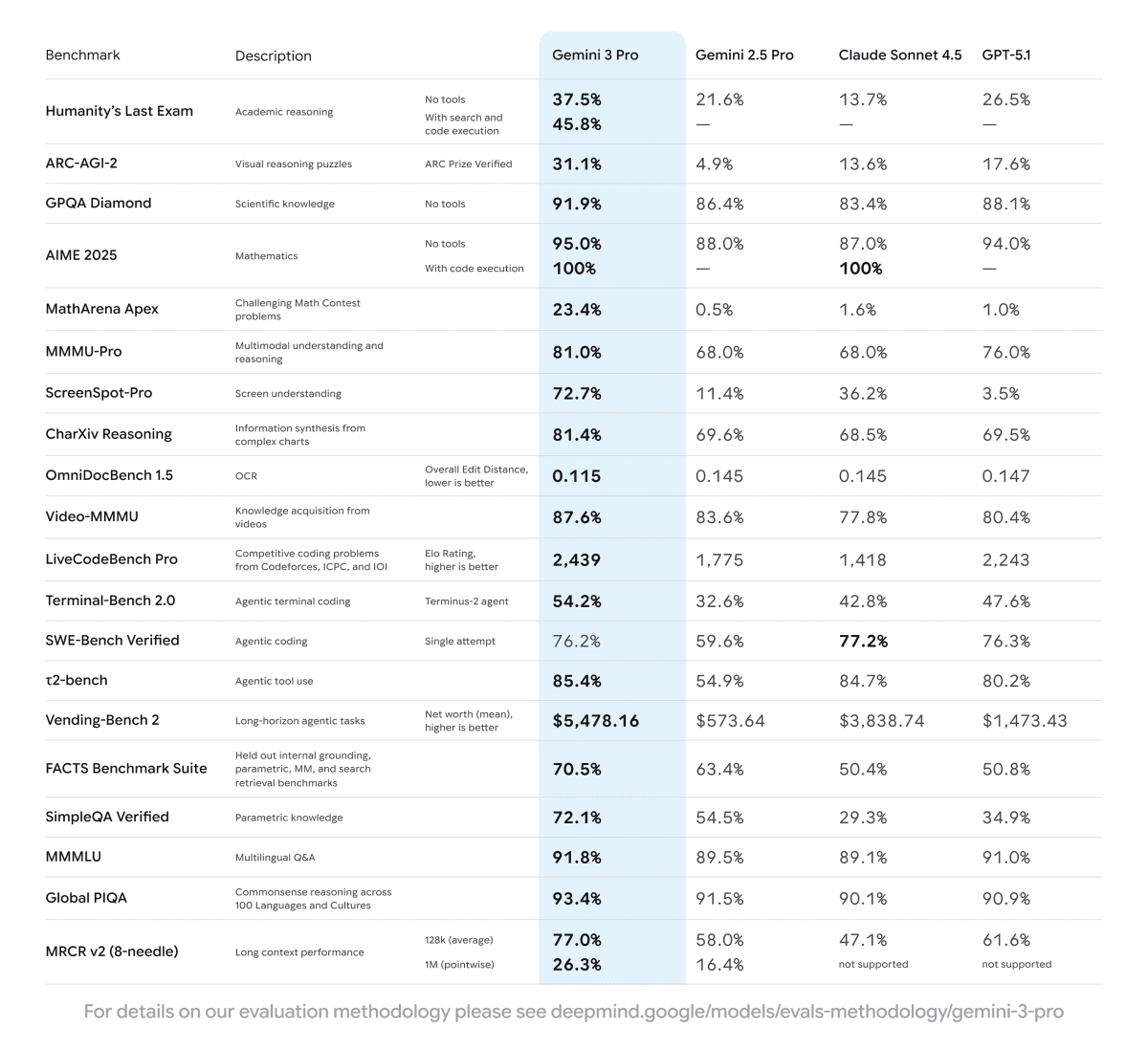
実際にOCRを試してみる
実際に各モデルがどれくらいの認識レベルなのか、ocr-benchmarkのデータセットから1件を使って検証してみました。
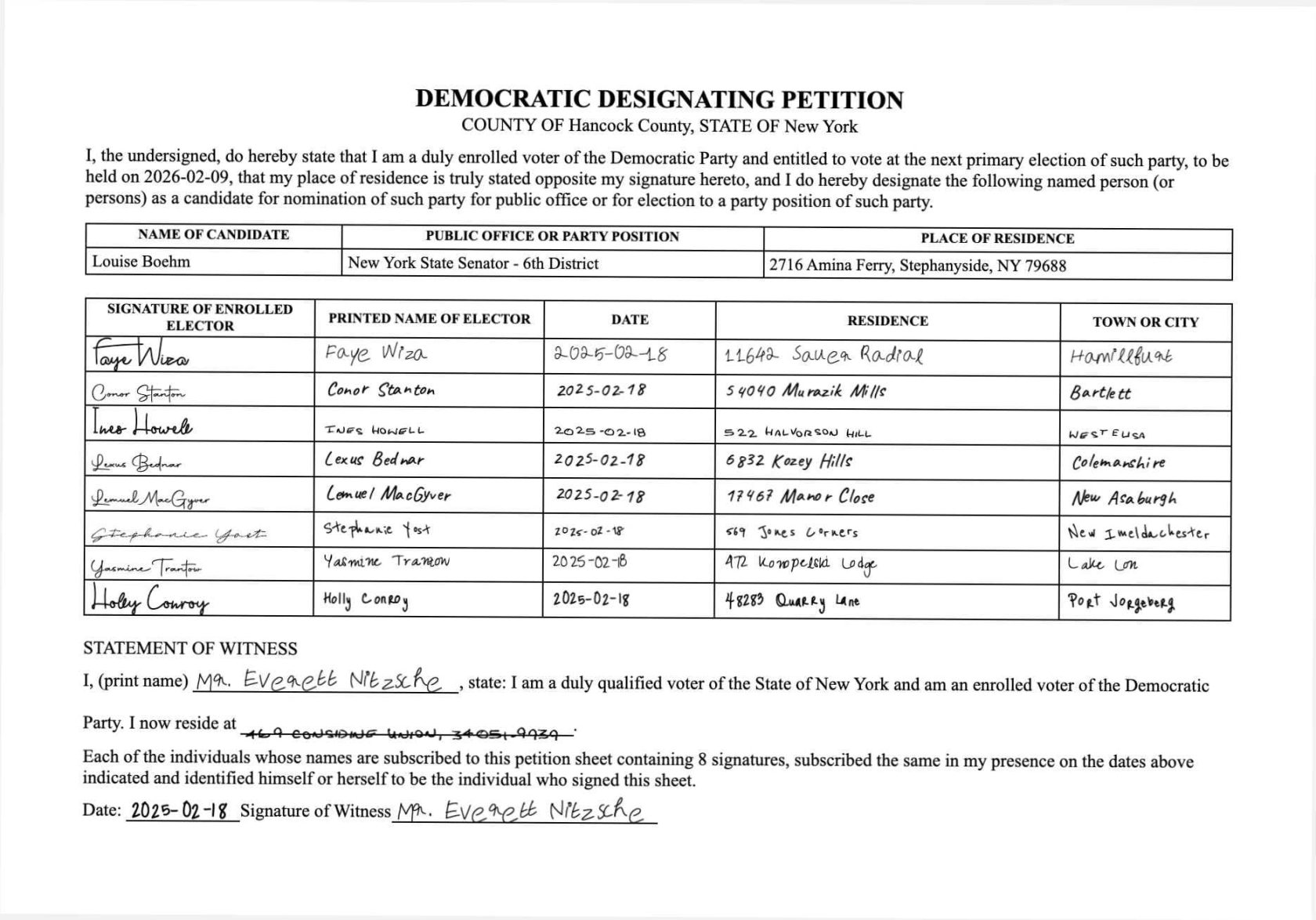
正解データ(手書き1行目)
{
"date": "2025-02-18",
"town": "Hamillfurt",
"printName": "Faye Wiza",
"residence": "11642 Sauer Radial"
}この情報を元に、マルチモーダルならではの使い方として「OCR+質問」形式で検証してみます。
質問内容
Faye Wizaの住居と街はそれぞれどこと書かれていますか?
Gemini 3 Pro の出力結果
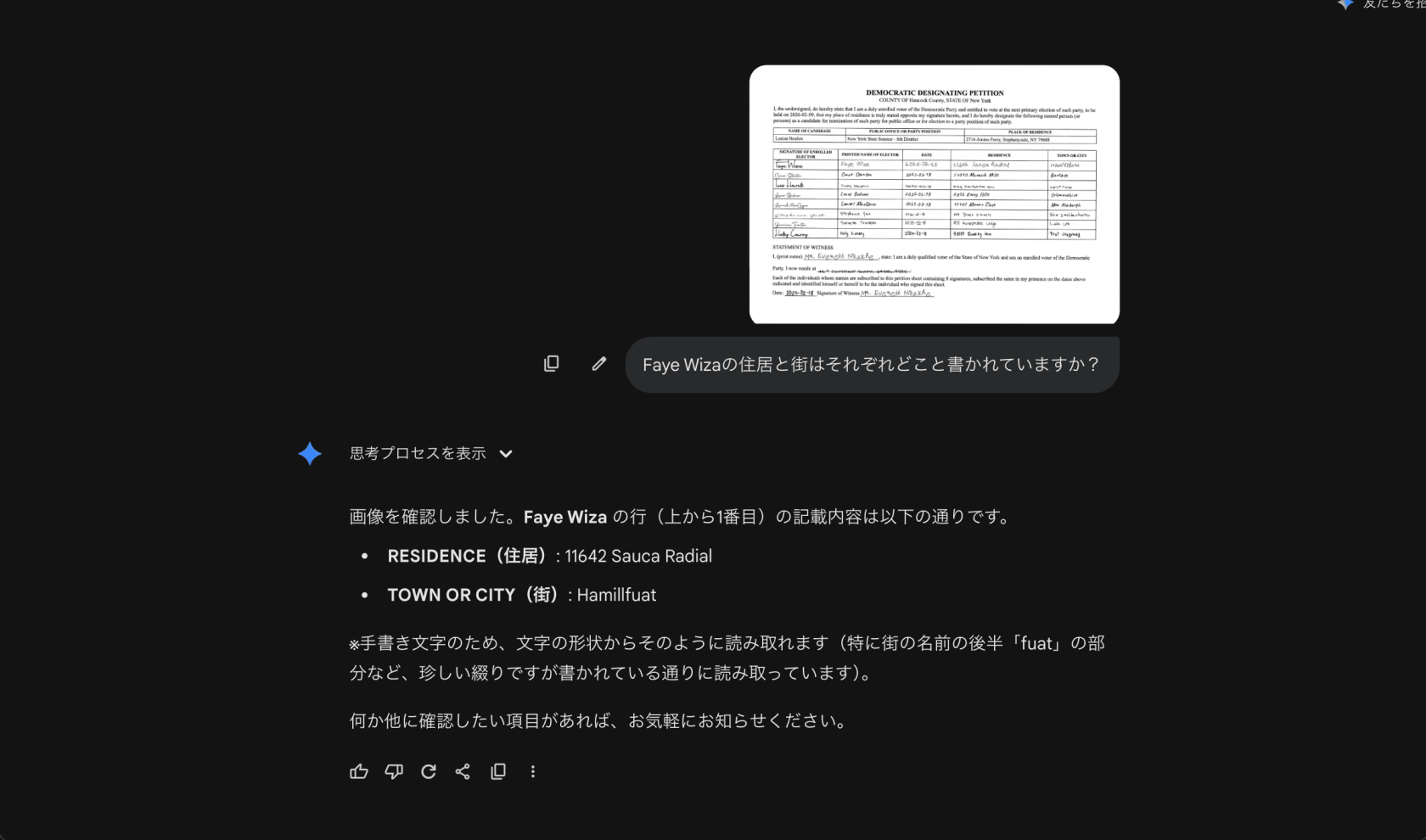
画像を確認しました。Faye Wiza の行(上から1番目)の記載内容は以下の通りです。
- RESIDENCE(住居): 11642 Sauca Radial
- TOWN OR CITY(街): Hamillfuat
※手書き文字のため、文字の形状からそのように読み取れます(特に街の名前の後半「fuat」の部分など、珍しい綴りですが書かれている通りに読み取っています)。
Claude Opus 4.5 の出力結果

画像を確認すると、Faye Wizaの情報は以下の通りです:
- 住居(RESIDENCE): 11642 Sauea Radial
- 街(TOWN OR CITY): Hamellburg
GPT-5.1 の出力結果

画像を確認しました。Faye Wiza の記載内容は以下の通りです:
- 住居(RESIDENCE): 11664? Saucer Radral(筆跡からすると「11664a」または「11664?」のようにも見えます)
- 街(TOWN OR CITY): Homrellbank
読みづらい部分がありますが、上記のように解釈できます。
考察
| モデル | 住居の認識 | 街の認識 | 総評 |
|---|---|---|---|
| 正解 | 11642 Sauer Radial | Hamillfurt | – |
| Gemini 3 Pro | 11642 Sauca Radial | Hamillfuat | 最も正解に近い |
| Claude Opus 4.5 | 11642 Sauea Radial | Hamellburg | 惜しい |
| GPT-5.1 | 11664? Saucer Radral | Homrellbank | 誤認識が多い |
手書き文字の認識では、Gemini 3 Proが最も正解に近い結果を出しました。
一方で、すべてのモデルで細かい文字の誤認識が発生しており、手書き文字のOCRはまだ完璧ではないことがわかります。実務で使用する際は、人間によるダブルチェックが推奨されます🐰
DeepSeek OCR
DeepSeek OCRは、中国のDeepSeek社が開発したオープンソースのマルチモーダルOCRで、誰でも無料で使えるのが大きな特徴です。
何がすごいのか
DeepSeek OCRの正式名称は「DeepSeek-VL2」で、Vision-Language Model(VLM)として開発されました。
もともと「コンテキスト圧縮技術」として開発されたのが面白いポイント。文書画像を効率よく圧縮する過程で、結果的に高精度なOCRとしても機能することがわかったのです。
驚きの性能
- データを7-20倍に圧縮しても97%以上の精度を維持
- 処理コストが従来の1/10以下
できること
文書のMarkdown変換
複雑なPDFファイルを、見出しや表の構造を保ったままMarkdown形式に変換できます。技術文書やレポートの構造化に最適です。
幅広い文書に対応
- 手書き文字の高精度認識
- 数式や化学式の理解(LaTeX形式で出力)
- 表やグラフの構造保持
オープンソースのメリット
DeepSeek OCRはオープンソースなので、自社のサーバーで動かすことができます。
- セキュリティ – データを外部に送る必要がない
- コスト削減 – API課金なしで大量処理可能
- カスタマイズ – 自社データでファインチューニング可能
機密性の高い文書を扱う企業にとって、オンプレミス運用できる点は大きな魅力ですね🐰
まとめ
AIによるOCRは、文書処理の世界を大きく変えています。
AI OCR(マルチモーダル)の魅力
- 高精度 – 手書きでも複雑な文書でも正確に読み取り
- 効率化 – 業務効率が飛躍的に向上
- ミス削減 – 人的ミスを大幅に減らせる
マルチモーダルLLMならではの強み
従来のAI OCRと比べて、マルチモーダルLLMには以下のような独自の強みがあります。
文脈理解による自動補正
「I1linois」→「Illinois」のように、文脈から正しい文字を推測して自動修正できます。従来OCRでは難しかった誤認識の自動補正が可能になりました。
質問形式での情報抽出
「この請求書の合計金額は?」「署名者の名前は?」といった自然言語での質問に直接回答できます。OCR結果を別途解析する手間が省けるのは大きなメリットです。
文書構造の意味理解
単に文字を読み取るだけでなく、「ここは表のヘッダー」「ここは注釈」「ここは署名欄」といった文書の意味構造まで理解できます。
多言語混在文書への対応
日本語と英語が混在するビジネス文書も、言語を自動判別しながらシームレスに処理できます。
紙の文書をデジタル化したいと考えている方は、ぜひAI OCRの導入を検討してみてください。特にマルチモーダルLLMは、フォーマットが決まっていない資料のOCRや、文脈を理解して認識率を向上させたい場面で威力を発揮します。きっと業務効率化の強い味方になってくれるはずです🐰
参考資料
- Tesseract OCR – GitHub
- PaddleOCR – GitHub
- Paddle OCR vs. Tesseract: A Comparative Performance Analysis – IJRPR
- DeepSeek-VL2 – GitHub
- OCR Benchmark Dataset – Hugging Face
あなたも生成AIの活用、始めてみませんか?
生成AIを使った業務効率化を、今すぐ始めるなら
「初月基本料0円」「ユーザ数無制限」のナレフルチャット!
生成AIの利用方法を学べる「公式動画」や、「プロンプトの自動生成機能」を使えば
知識ゼロの状態からでも、スムーズに生成AIの活用を始められます。
taku_sid
https://x.com/taku_sid
AIエージェントマネジメント事務所「r488it」を創立し、うさぎエージェントをはじめとする新世代のタレントマネジメント事業を展開。AI技術とクリエイティブ表現の新たな可能性を探求しながら、次世代のエンターテインメント産業の構築に取り組んでいます。
ブログでは一つのテーマから多角的な視点を展開し、読者に新しい発見と気づきを提供するアプローチで、テックブログやコンテンツ制作に取り組んでいます。「知りたい」という人間の本能的な衝動を大切にし、技術の進歩を身近で親しみやすいものとして伝えることをミッションとしています。







スマートフォンでもAI活用!
アプリ版「ナレフルチャット」配信中
iPhoneはこちら


Androidはこちら




