PLUS
生成AIコラム
ChatGPTに学習させないオプトアウトとは?設定方法からリスク対策例まで解説

目次:
はじめに
「ChatGPTに入力した情報が学習されて他人の回答に使われないか心配」「会社の機密情報を入力しても大丈夫なのか」「オプトアウトという設定があるらしいが、具体的に何が変わるのか」といった不安を抱えるビジネスパーソンは多いでしょう。
その課題を解決する方法が、ChatGPTのオプトアウト設定です。適切に設定すれば、入力したデータがAIの学習に使われることを防ぎ、情報漏洩のリスクを大きく軽減できます。ただし「学習させない」ことと「履歴を残さない」ことは全く別の概念であり、多くの記事で混同されている点には注意が必要です。
本記事では、ChatGPTのオプトアウトの仕組みと具体的な設定方法、履歴やメモリとの違い、さらに企業で実施すべきセキュリティ対策まで網羅的に解説します。ChatGPTを安全に業務活用したい方は、ぜひ参考にしてください。
生成AIの社内利用をお考えの企業様へ
ナレフルチャットは業界最安級のコストパフォーマンスで、社内の生成AI活用を支援するツールです。デフォルトでデータ学習がオフになっており、情報漏洩のリスクを抑えながら、誰でも簡単にAIを業務で活用できます。企業のAI導入を検討している方は、こちらをご覧ください。ChatGPTに学習させないオプトアウトとは?
ChatGPTのオプトアウトとは、ユーザーが入力した会話データをOpenAIがAIモデルの学習に使用しないよう設定することです。この設定を有効にすると、プロンプトや回答内容が将来のモデル改善のためのデータセットに含まれなくなります。
多くの企業がChatGPTの業務利用を検討する際、最も懸念するのが「入力した情報が学習されて、他のユーザーの回答に反映されるのではないか」という点です。オプトアウト設定はこの懸念に対する有効な対策となります。
ここでは、ChatGPTがどのように学習しているのか、そして実際に学習データが原因で問題になった事例を見ていきます。
- ChatGPTの学習の仕組み
- 学習データが漏洩した事例
ChatGPTの学習の仕組み
ChatGPTは、ユーザーとの会話データを収集し、AIモデルの改善に活用しています。具体的には、入力されたプロンプトとそれに対する回答、ユーザーのフィードバック(良い回答・悪い回答の評価)などが学習データとして蓄積されます。
この学習プロセスを通じて、ChatGPTはより自然な会話や的確な回答ができるようになります。ただし、デフォルト設定では個人情報や機密情報を含むデータも学習対象となる可能性があるため、ビジネス利用では注意が必要です。
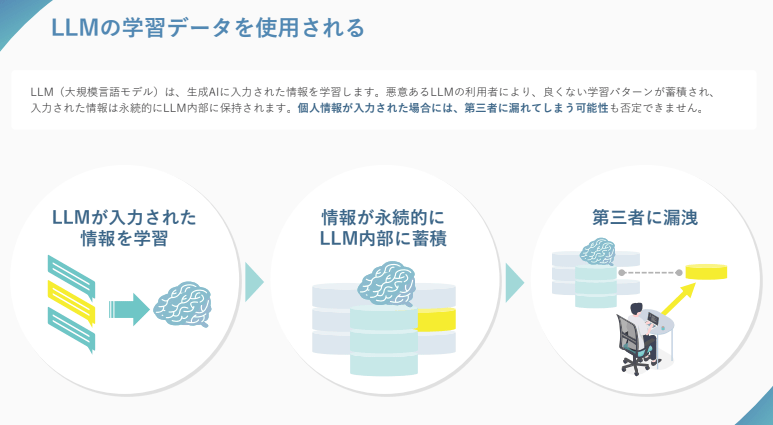
学習された情報は、第三者がChatGPTを使用した際の出力に使用される可能性があり、意図しない漏洩に繋がる恐れがあります。そのため、機密性の高い情報を扱う場合は、オプトアウト設定(※)が推奨されます。
※ユーザーが入力した会話データをOpenAIがAIモデルの学習に使用しない設定
学習データが漏洩した事例
2023年、韓国のサムスン電子でChatGPTに関連する情報漏洩インシデントが発生しました。社員が、社外秘のソースコードをChatGPTに入力してしまったことが原因です。
詳細な経緯は公開されていませんが、社員がChatGPTを使用した際、社内コードを外部サーバー(ChatGPT)に送信してしまいました。これにより、入力されたデータはOpenAIのサーバーに保存され、学習データとして使用される可能性や、他のユーザーの回答に反映されるリスクが生じたのです。
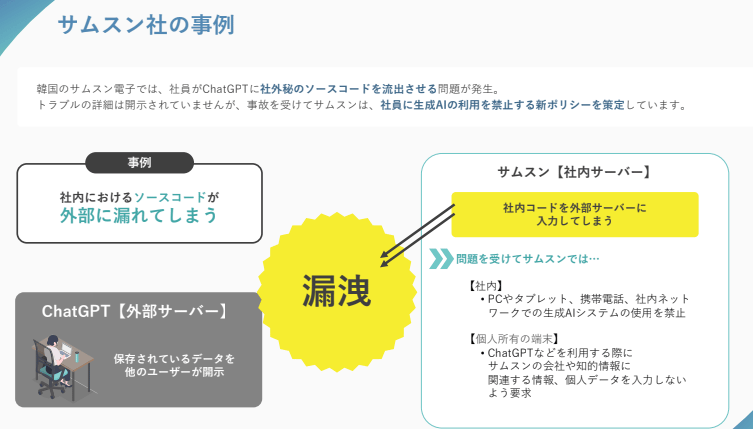
この事態を受けてサムスンは、社員による生成AIの利用を制限する新たなポリシーを策定しました。具体的には、社内のPCやタブレット、携帯電話、ネットワークでの生成AIシステムの使用を全面的に禁止し、個人所有の端末でChatGPTなどを利用する際も、サムスンの企業情報や知的財産に関連する情報、個人データを入力しないよう厳格に求めています。
この事例が示すのは、オプトアウト設定をしないまま機密情報を入力すると、意図せずデータが外部に流出するリスクがあるということです。
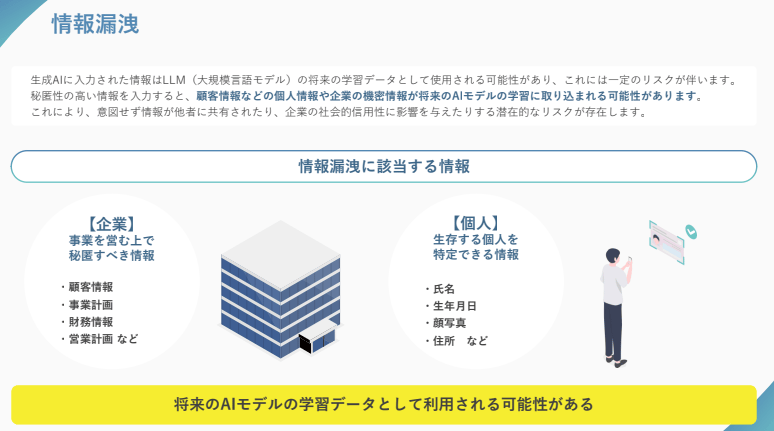
特に技術文書やソースコード、顧客情報などを扱う場合は、事前の対策が不可欠になります。
ChatGPTのオプトアウトの設定方法
ChatGPTのオプトアウトは、設定画面から簡単に有効化できます。また、より確実にデータ学習を防ぎたい場合は、OpenAIの申請フォームから正式なオプトアウト申請を行うことも可能です。
ここでは、2つの設定方法を具体的に解説します。それぞれの方法で保護される範囲が異なるため、用途に応じて使い分けることが重要です。
- 1.設定画面から学習をオフにする
- 2.申請フォームからオプトアウト申請をする
なお、ChatGPTのBusinessプラン(旧Teamプラン)やEnterpriseプランでは、デフォルトで入力データが学習に使用されない設計になっています。法人利用を検討している場合は、こうした企業向けプランの導入も選択肢となります。
詳しくは、以下の記事をご参照ください。
参考記事: ChatGPT Enterpriseとは?他プランとの違い・導入時の注意点を解説
1. 設定画面から学習をオフにする
最も簡単な方法は、ChatGPTの設定画面から、オプトアウトの設定を変更することです。
まず、画面左下の自分のアカウントをクリックし、「設定」をクリックしましょう。
設定画面が開けたら、「データコントロール」から「すべての人のためにモデルを改善する」をクリックします。
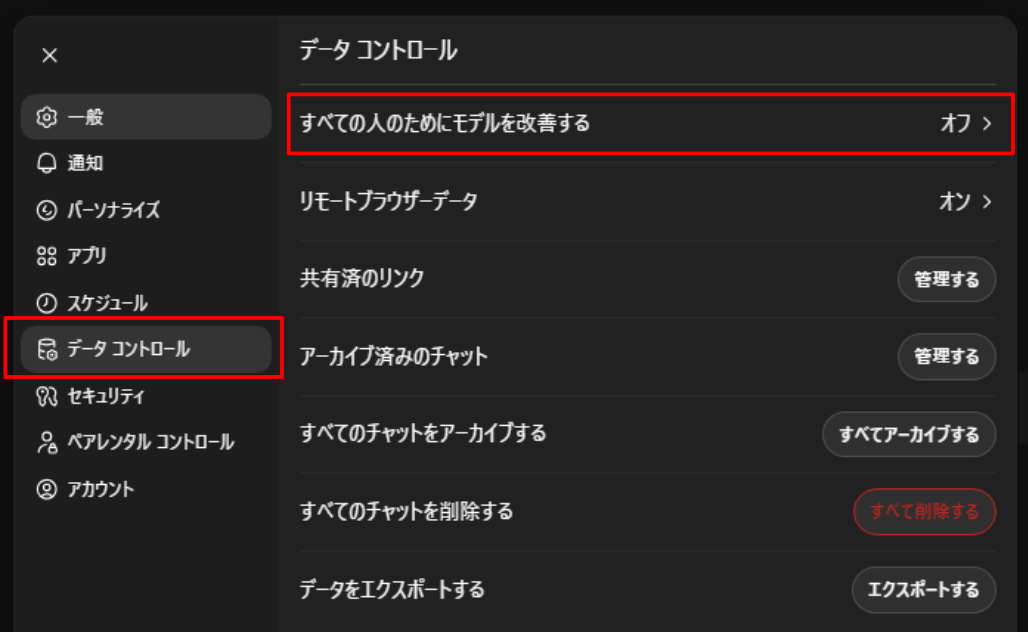
「モデルの改善」画面が開けたら、「すべての人のためにモデルを改善する」のスライドボタンをクリックしてOffにしましょう。下記画像のようになっていれば完了です。
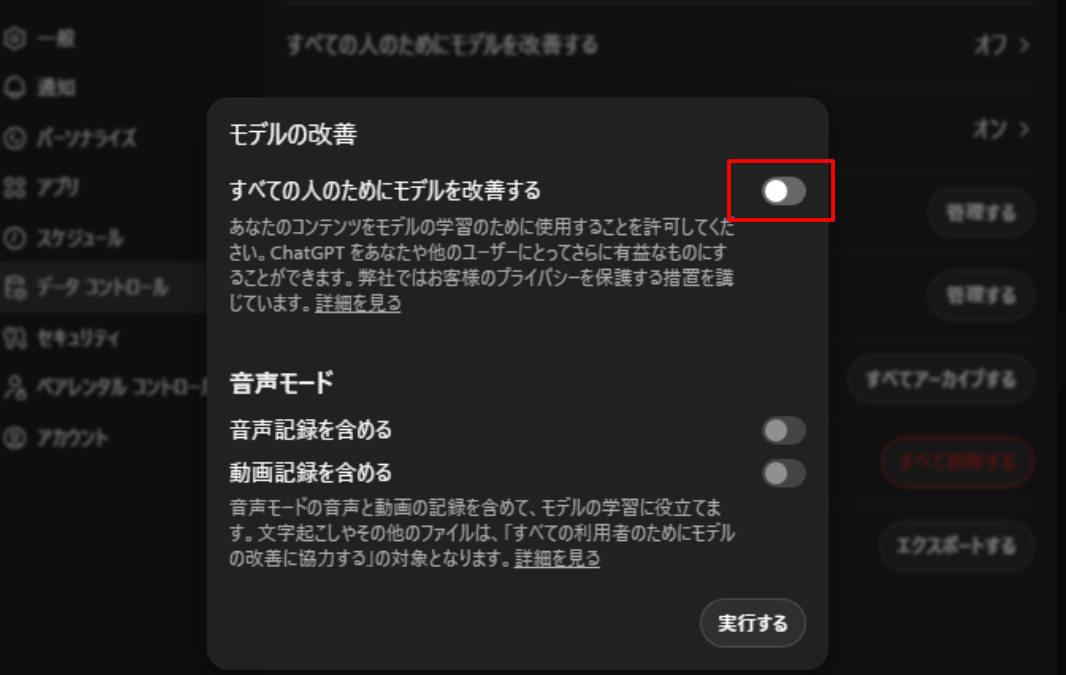
設定変更は即時反映されるため、これで設定完了となり、ログアウトや再読み込みする必要はありません。また、設定はユーザーごとに保持されるため、同じアカウントで別のブラウザ・アプリでも設定は引き継がれます。
2. 申請フォームからオプトアウト申請をする
より確実にデータ学習を防ぎたい場合は、OpenAI Privacy Portalにある申請フォームから申請を行う方法が有効です。
ここから申請することで、できることは以下の4点です。
- ChatGPTアカウントの詳細、アップロードしたファイル、生成したファイル、ChatGPT の会話、ログ、支払い情報(追加されている場合)など個人データのコピーの取得
- モデルの改善のためにコンテンツが使用されることの永久的なオプトアウト
- ChatGPT アカウントの削除
- カスタム GPT の削除
- ChatGPTの回答から学習されてしまった個人データの削除
それではここからは申請の方法を解説していきます。
まず、OpenAI Privacy Portalにアクセスし、画面右上「Make a Privacy Request/プライバシーリクエストを申請する」をクリックしましょう。(※デモ画像は日本語訳しています)

クリックすると、アカウントの有無を聞かれるので、回答しましょう。(以降、アカウントを持っている前提で解説を進めます)
そうすると、プライバシーコントロール画面が出るので、そこの「Do not train on my content/ 私のコンテンツでトレーニングしないでください」をクリックしましょう。
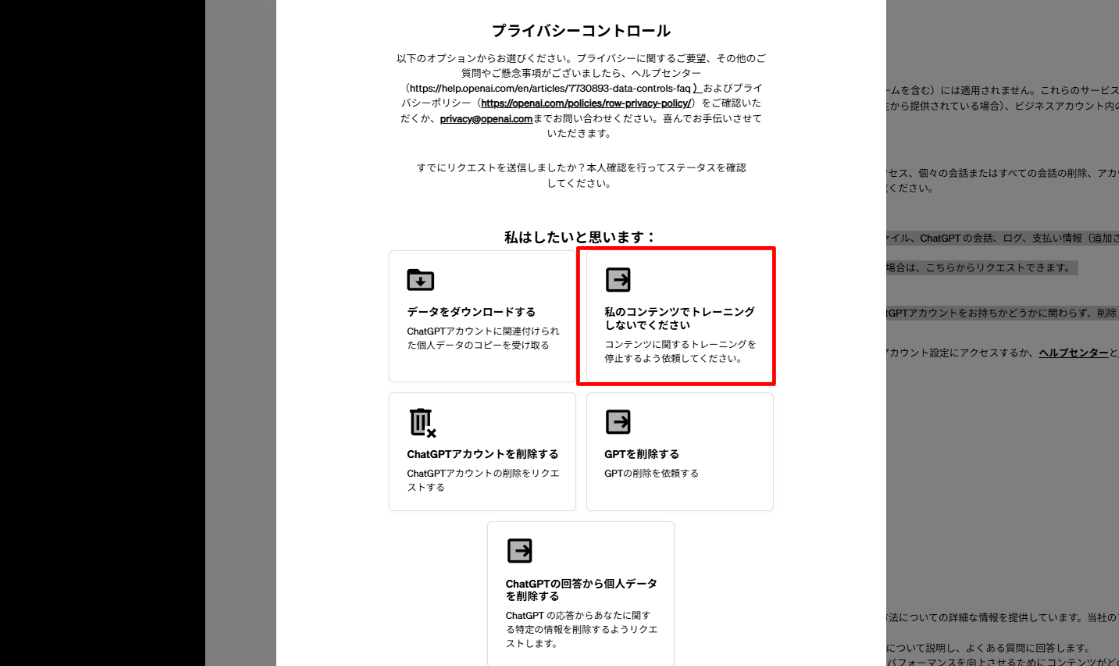
ブラウザ上でのログインを要求されるので、メールアドレスとパスワードを入力し、ログインしてください。
最後に、注意文が出てくるので、チェックボックスにチェック、居住国/州を自身の居住国に設定し、「Submit Request/リクエストを送信」をクリックしましょう。

これで操作完了です。
申請が承認されると、該当するアカウントまたは組織から送信されるすべてのデータが学習対象から除外されます。リクエストの処理が完了すると、メールが送信されてくるので、そこで対応が完了したかをチェックしてください。
申請処理には数日から数週間かかる場合があるため、急ぎでオプトアウトしたい場合は、まず設定画面からの変更を行い、並行して申請フォームも提出するのが効果的です。
「学習」と「メモリ」や「履歴」は全くの別物
ChatGPTの「学習」「メモリ」「履歴」は、それぞれ異なる機能です。これらの機能は混同して理解されやすいですが、正しく理解しておかないと、意図しない情報漏洩につながる可能性があります。
学習は、OpenAIがChatGPTなどのAIモデルを改善するために会話データを使用することを指します。オプトアウト設定で制御できるのはこの部分です。学習に使われたデータは、将来的に他のユーザーの回答生成に影響を与える可能性があります。
メモリには2種類があります。1つ目は「保存されたメモリ」で、ユーザーが覚えておくように指示したプロフィール情報を記憶し続ける機能です。
2つ目は「チャット履歴の参照」で、過去の会話内容を参照してより適切な回答を返す仕組みです。どちらも個人のアカウント内で完結し、他のユーザーには共有されません。
つまり、別のチャットで話した内容が、違うチャットでも回答に反映されるため、よりパーソナライズドされた出力を得ることが出来るのです。
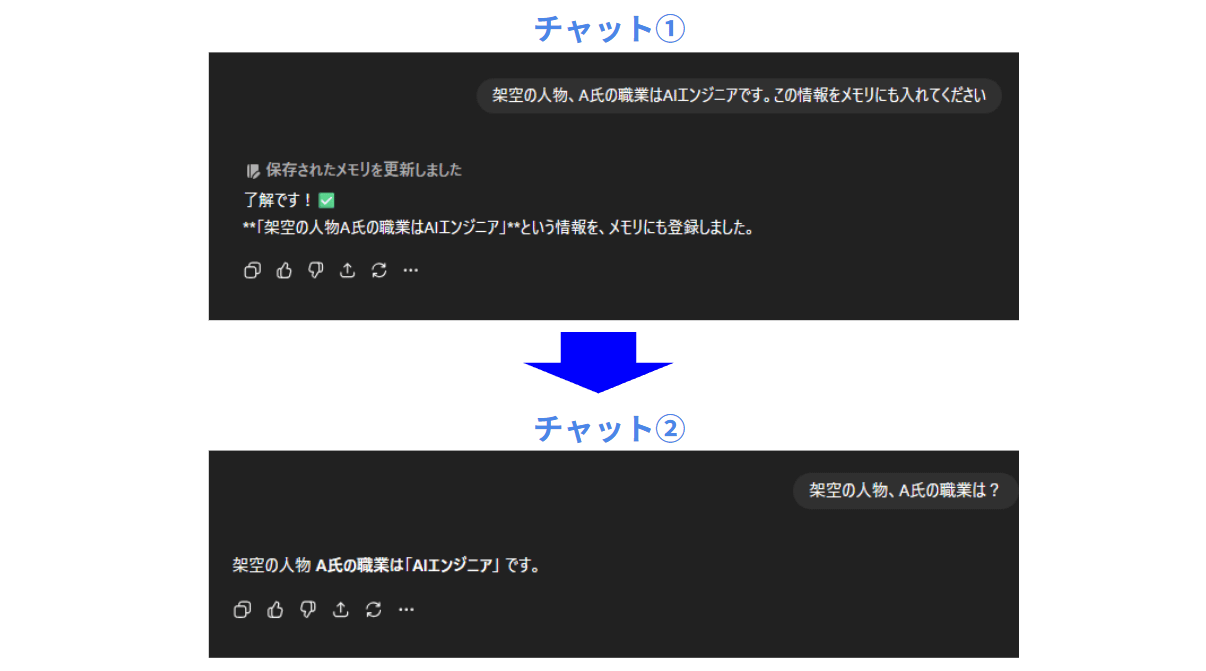
履歴は、過去の会話を後から見返すための機能です。ChatGPTの画面左側、サイドバーに表示される会話リストがこれに該当します。
以下の表で、各機能の違いと制御方法をまとめました。
| 機能 | 何が起きる? | 他ユーザーに影響する? |
|---|---|---|
| 学習 (モデル改善) | 会話内容が学習用データに使われる | 影響しうる (将来の回答精度に反映される可能性) |
| メモリ (保存されたメモリ) | プロフィールや好みなどを記憶 | しない |
| メモリ (チャット履歴の参照) | 過去会話を参照して回答を最適化 | しない |
| 履歴 (サイドバーの会話一覧) | 会話ログが一覧に残る | しない |
オプトアウトを設定しても、メモリや履歴は通常通り機能します。逆に、履歴を削除してもオプトアウトしていなければ、その会話データは学習に使われる可能性があります。それぞれの機能を正しく理解し、目的に応じて設定することが重要です。
法人向け生成AIサービス「ナレフルチャット」では、学習データに利用されない”API”を活用しているため入力内容は学習データに一切利用されません。また、一部モデルはZDRに対応しており、高度な機密性を持つ情報も安心してナレフルチャットで活用することが可能です。
初月無料で生成AIが利用できるトライアル期間も用意しておりますので、生成AIの利活用を検討している企業様は、是非一度導入をご検討ください。ChatGPTに履歴やメモリを残さない方法
学習設定とは別に、履歴やメモリを残さない設定も可能です。これらの設定を活用することで意図しないタイミングでその情報が出力することを防げるため、より安全にChatGPTを利用できます。
ここでは、履歴やメモリを残さないための2つの方法を解説します。どちらもシンプルな操作で設定でき、必要に応じてオンオフを切り替えられます。
- 設定画面からメモリの設定をする
- 一時チャットを利用する
設定画面からメモリの設定をする
1つ目は、ChatGPTの設定画面からメモリに関する設定をする方法です。
メモリ機能を無効化するには、まずChatGPT画面左下の自分のアカウントから、「設定」をクリックし、設定画面を開きましょう。
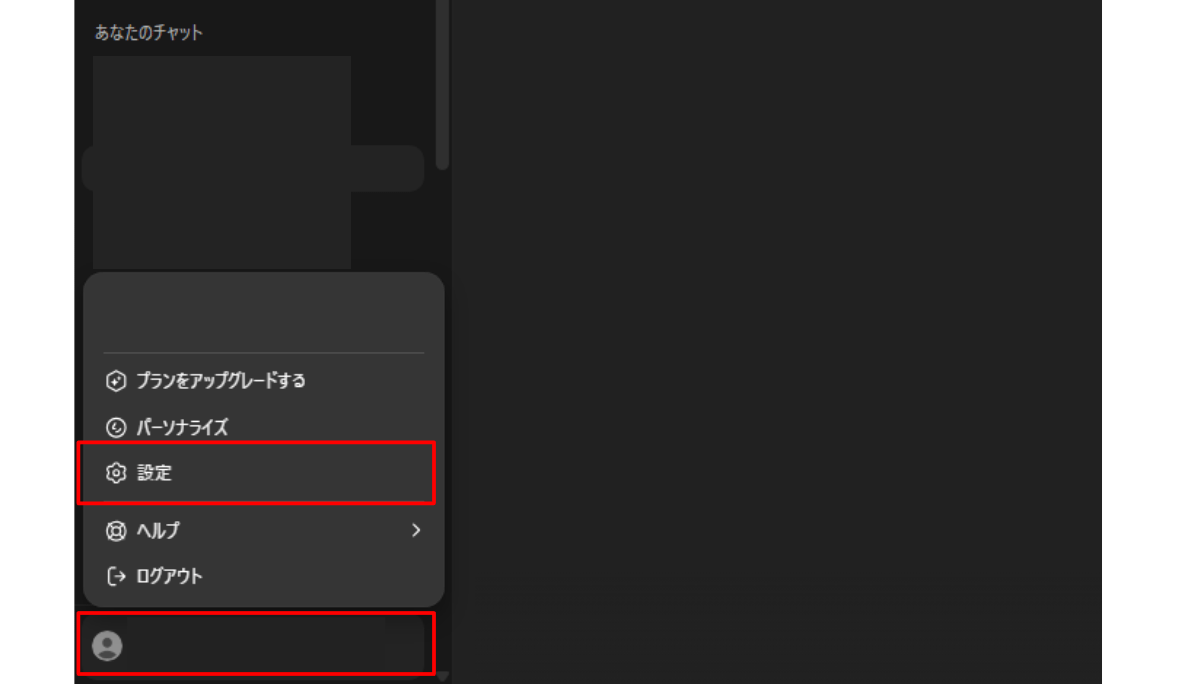
設定画面内の「パーソナライズ」をクリックし、下の方にスクロールしたところにある「メモリ」をオフにします。この設定を行うと、ChatGPTは会話から情報を記憶せず、毎回ゼロからの会話として扱われます。
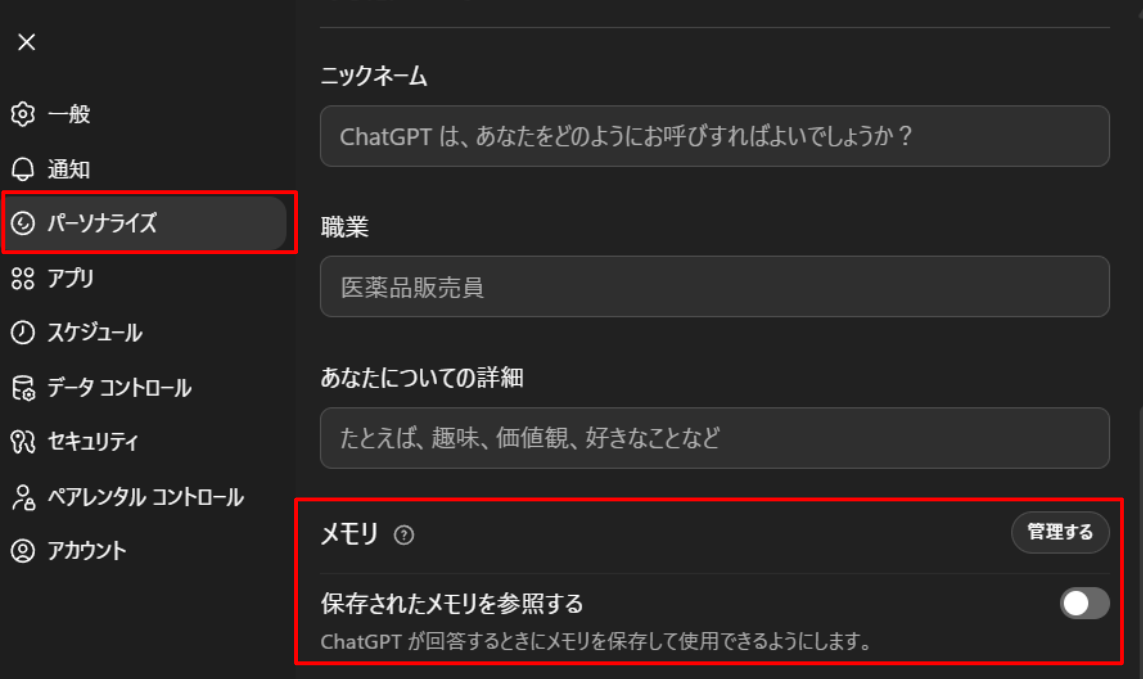
この設定を行うと、ChatGPTは会話から情報を記憶せず、毎回ゼロからの会話として扱われます。
「管理する」をクリックすると個別のメモリが表示されるため、そこから特定のメモリだけを削除することも可能です。
一時チャットを利用する
2つ目が、ChatGPTの一時チャット機能を利用する方法です。画面右上の点線で吹き出しの形を作っているアイコンをクリックすると、一時チャット画面に切り替わります。
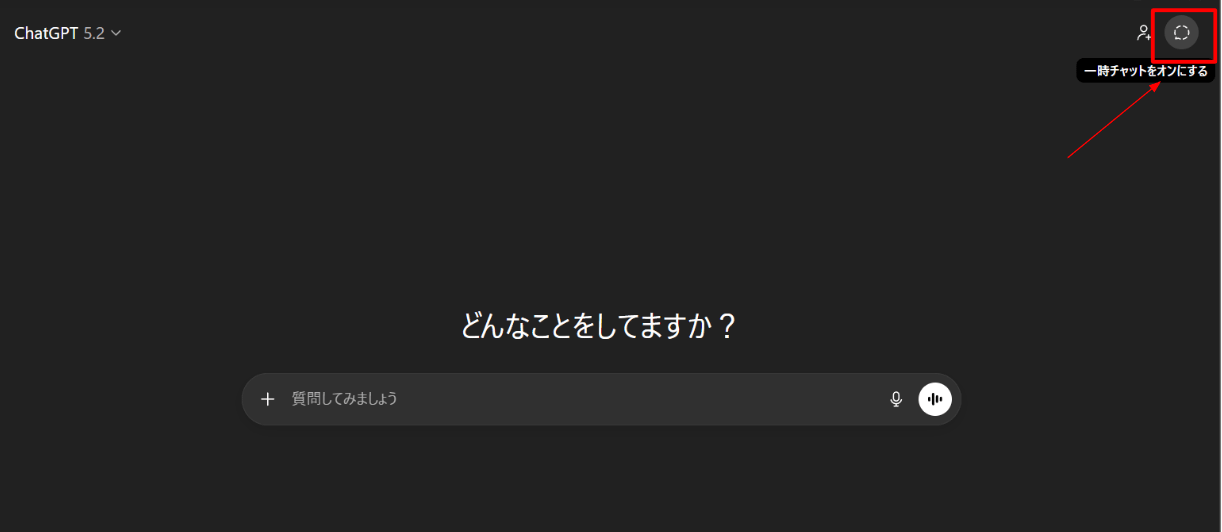
以下の画像の画面になれば成功です。一時チャットでは、会話内容が履歴に保存されず、メモリにも記録されません。また、その会話データは学習にも使用されないため、完全にプライベートな状態で利用できます。
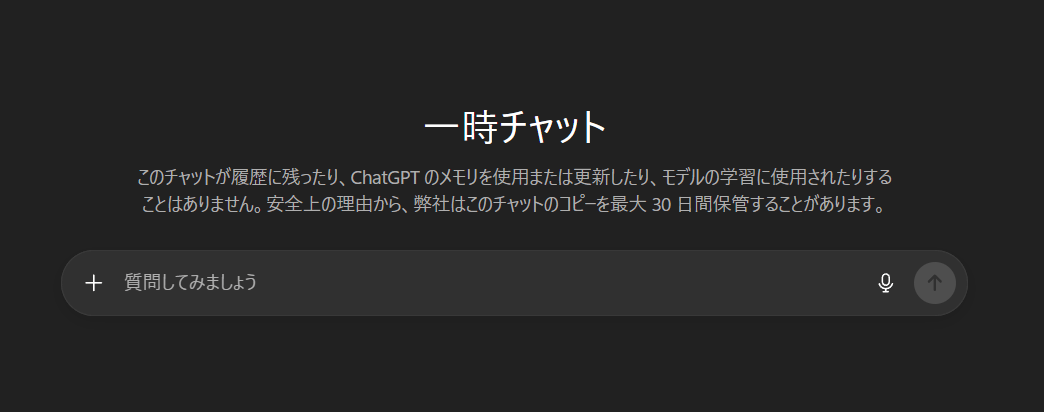
この機能は、パスワードや個人情報、機密性の高いビジネス情報を一時的に扱う場合に特に有効です。通常の会話と一時チャットを使い分けることで、利便性とセキュリティのバランスを取ることができます。
オプトアウト以外の情報漏洩・セキュリティ対策例
オプトアウト設定だけでは、完全にリスクを防げるわけではありません。ChatGPTを業務で安全に活用するには、複数の対策を組み合わせることが重要です。
ここでは、企業が実施すべき4つの情報漏洩・セキュリティ対策を紹介します。これらを実践することで、AIツールの利点を享受しながら、情報管理のリスクを最小限に抑えられます。
- APIを利用する
- 個人情報や機密情報を入力しない
- 利用者のAIリテラシーを向上させる
- 法人向け生成AIサービスを導入する
APIを利用する
ChatGPTのAPIを使用すれば、入力データが学習に使用されることはありません。API経由のデータは、OpenAIの利用規約上、モデルのトレーニングには使われない仕様になっています。(※不正利用検知などの目的で一定期間保持される場合があります)
参照:「Data controls in the OpenAI platform」OpenAI
APIを導入すれば、自社のシステムやアプリケーションにChatGPTの機能を組み込みながら、データの扱いを厳密に管理できます。特に大量のデータを処理する場合や、既存システムとの連携が必要な場合に有効です。
ただし、API利用にはある程度の技術的知識が必要で、コストも発生します。導入の際は、自社のリソースや予算を考慮して検討することが大切です。
個人情報や機密情報を入力しない
最も基本的な対策は、そもそも機密情報をChatGPTに入力しないことです。オプトアウト設定をしても、入力データは一定期間OpenAIのサーバー上に保管されるため、完全にリスクがゼロになるわけではありません。
具体的には、顧客の氏名や住所、社員の個人情報、未発表の製品情報、契約書の詳細などは入力を避けるべきです。
どうしても入力が必要な場合は、情報を匿名化したり、一般化した表現に置き換えたりする工夫が求められます。
「この情報が外部に漏れたらどうなるか」という視点で、入力内容を慎重に判断することが重要です。少しでもリスクがある情報は、代替手段を検討するようにしましょう。
利用者のAIリテラシーを向上させる
技術的な対策だけでなく、従業員のAIリテラシー向上も不可欠です。ChatGPTの仕組みやリスクを理解していないと、無意識のうちに機密情報を入力してしまう可能性があります。
社内研修や利用ガイドラインの整備を通じて、「どんな情報を入力してよいか」「どんな場面で使うべきか」を明確にすることが大切です。実際の事例を交えて説明すると、理解が深まりやすくなります。

また、定期的に利用状況をモニタリングし、不適切な使い方がないかチェックする体制も整えておくと、問題の早期発見につながります。
法人向け生成AIサービスを導入する
企業での本格的なAI活用を考えるなら、法人向けの生成AIサービスの導入が効果的です。こうしたサービスは、セキュリティ対策が最初から組み込まれており、管理機能も充実しています。
例えば、データの学習利用が完全にオフになっていたり、利用ログが詳細に記録されたり、管理者による一元管理が可能だったりします。ChatGPTのEnterpriseプランや、他社が提供する法人向けAIツールがこれに該当します。
初期コストがかかる場合がありますが、長期的に見れば情報漏洩のリスク低減や管理工数の削減により、十分に投資対効果が見込めます。
当社が提供するナレフルチャットでは、学習データに利用されないAPIを活用しているほか、データベースの暗号化や通信の保護など、企業レベルのセキュリティ対策を実装しています。
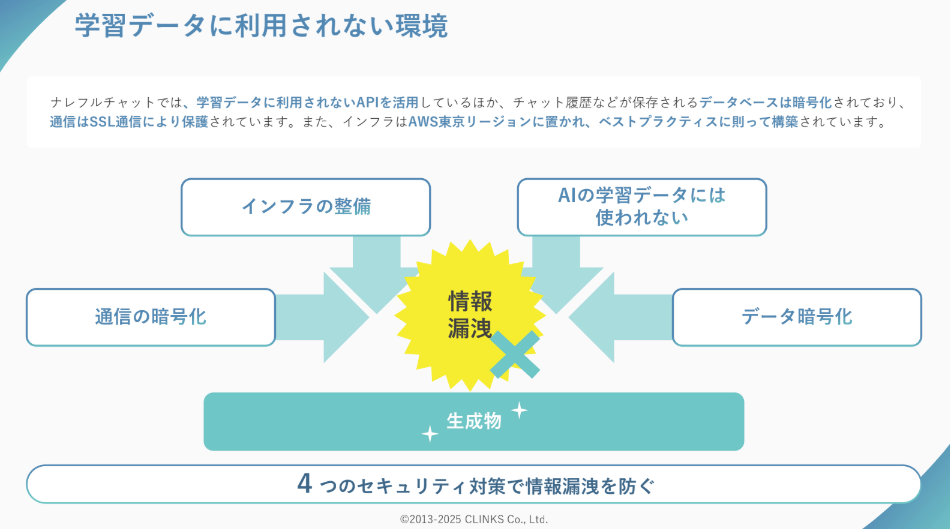
これにより、法人でも情報漏洩を気にすることなく、安全に生成AIを活用することが出来ます。
ナレフルチャットならリスク対策しつつ生成AIを活用できる
ChatGPTのオプトアウト設定や各種セキュリティ対策を実施しても、完全にリスクをゼロにすることは難しいのが現状です。特に中小企業では、専任の管理者を置くことが難しく、従業員への教育も十分に行き届かないケースが多く見られます。
ナレフルチャットは、こうした企業の課題を解決する法人向け生成AIチャットサービスです。ISMS認証(ISO27001)とプライバシーマークを取得したCLINKS株式会社が開発・運営しています。

学習データに利用されないAPIを活用しているだけでなく、2025年12月にはChatGPTとClaudeにおいてZDR(Zero Data Retention/ゼロデータ保持)に対応しました。
ZDRとは
ユーザーが入力したデータや生成された応答内容を、AIプロバイダー側に一切保存しない仕組みのこと。API利用で学習への利用を防ぐことはできますが、入力データ自体はプロバイダー側で一定期間保持されてしまいます。ZDR対応により、入力データがプロバイダー側で保持されることなく処理されるため、情報漏洩リスクを最小化できるのです。
参考記事:ナレフルチャット、ChatGPT・ClaudeでZDR(ゼロデータ保持)を実現~企業の機密情報を保存しない安心・安全な生成AI活用環境を提供~
また、社員のAIリテラシー向上支援のためのコンテンツや、誰でも生成AIを効率的に活用できるサポート機能も充実しています。
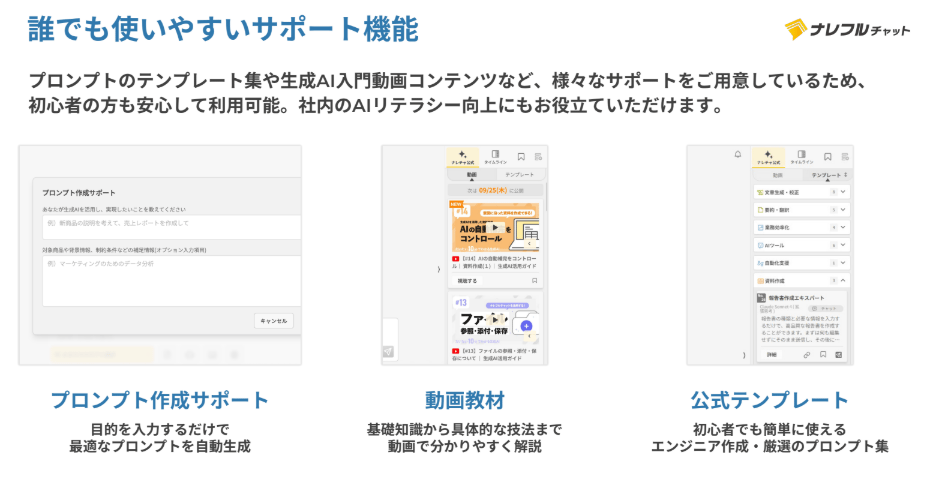
業界最安級の料金設定で、初めて生成AIを導入する企業でも手軽に始められます。無料トライアルも提供しているので、まずは実際の使い心地を確かめてみてはいかがでしょうか。
企業での生成AIの活用をお考えの方は、ぜひご検討ください。
ナレフルチャット運営チーム
法人向けクローズド生成AIチャットサービス「ナレフルチャット」の企画・開発・運用を手がけています。
プロンプト自動生成・改善機能や組織内でのノウハウ共有機能など、独自技術の開発により企業の生成AI活用を支援しています。
「AIって難しそう...」という心の壁を、「AIって面白そう!」という驚きで乗り越えていただけるように
日々刻々と変化する生成AI業界の最新動向を追い続け、魅力的な記事をお届けしていきます。








スマートフォンでもAI活用!
アプリ版「ナレフルチャット」配信中
iPhoneはこちら


Androidはこちら




