PLUS
生成AIコラム
うさぎでもわかる Gemini Omni Googleの新マルチモーダルAI

はじめに
こんにちは、2026年5月19日のGoogle I/Oで「Gemini Omni」が発表されました。テキスト・画像・音声・動画をひとつのモデルで束ねて推論し、最終的に音声付き動画を生成できる、Googleの新世代ネイティブマルチモーダルモデルです。
本記事では、Omniのコンセプトと強み、主要機能、実際の検証と考察まで一気に整理していきます。これから動画生成AIをプロダクトや業務に組み込もうとしているエンジニアの方の判断材料になればうれしいです。
生成AIの社内利用をお考えの企業様へ
ナレフルチャットは初心者でも使いやすい設計で、組織全体への生成AI浸透を支援するツールです。プロンプト自動生成機能や社内共有機能により、AIリテラシーに差があっても全員が活用できます。企業のAI導入を検討している方は、こちらをご覧ください。Gemini Omniとはなにか
Gemini OmniはGoogle DeepMindが開発した「任意の入力から任意のメディアを生成できる」ことを掲げる新しいマルチモーダルモデルファミリーです。最初のラインナップとして、2026年5月19日に「Gemini Omni Flash」が公開されました。
ポイントを箇条書きで押さえておきます。
- 発表 2026年5月19日 Google I/O 2026
- コンセプト Create anything from any input
- 最初のモデル Gemini Omni Flash(10秒の音声付き動画を生成)
- 入力モダリティ テキスト・画像・音声・動画の組み合わせ
- 出力モダリティ 現状は音声付き動画(今後画像・音声出力も対応予定)
提供チャネルは以下の3つに分かれます。
- Geminiアプリ(Google AI Plus / Pro / Ultraサブスクライバー向け)
- Google Flow(クリエイティブスタジオ環境)
- Gemini APIとAgent Platform API(数週間以内に開発者向け展開予定)
VeoやImagenが「テキスト→動画」「テキスト→画像」と用途別の個別モデルだったのに対し、Omniは複数モダリティをひとつのモデルでネイティブに扱う点が大きな違いです。うさぎ的にはここが一番うさみみがピンと立つポイントでした🐰
マルチモーダルの強み
「マルチモーダル」自体は新しい言葉ではありませんが、Omniは「ネイティブに束ねる」ところまで踏み込んでいます。強みは大きく4つの軸で整理できます。
1. 任意の入力組み合わせを束ねて推論
人物画像、音声サンプル、背景動画、シナリオテキストを同時に渡すと、Omniは単純に連結するのではなく、全モダリティを横断して推論します。たとえば「この画像の人物が、この声で、この背景の中で、このセリフを話す動画」というような複合指示を、ひとつのプロンプトで成立させられます。
2. 物理法則を理解する世界モデル
重力、運動エネルギー、流体力学などを内部表現として持っています。これにより「次のフレームで何が起こるはずか」を予測してフレーム生成するため、過去モデルで頻発していた「物体が宙に浮いたまま」「水が形を失う」といった違和感が抑えられています。完璧ではないですが、世界モデルとしての解像度は1段あがっています。
3. 会話形式のマルチターン編集
これがOmni最大の独自性です。実際にうさぎがOmniで試してみた様子がこちら。Geminiアプリのチャット画面から、ターンを重ねて動画を編集していきます。

実際の操作画面 Geminiアプリ上で対話形式に動画を編集できる
ターン1 初回生成
ユーザ 中世の城壁を背景に、投石機が壺を発射する動画を生成してOmniが初回動画を生成しました。

画像はワンシーンの抜粋です。動画の全編をGeminiで再生する
ターン2 編集指示
ユーザ 背景を夜に変えてOmniは前回シーンのキャラクター・物理挙動・小道具の一貫性を維持したまま、時間帯だけを変更してきました。

画像はワンシーンの抜粋です。動画の全編をGeminiで再生する
各ターンで「キャラの同一性」「物理状態」「シーンの記憶」を保ったまま編集が積み上がります。これはアーキテクチャ寄りの差別化で、競合モデルでは現状再現が難しい挙動です。
4. Gemini本体の世界知識を活用
OmniはGeminiの言語モデルとしての知識ベースとつながっています。「平安時代の宮中の宴」「江戸時代の長屋」のような文化的なシーン指示でも、装束や建築様式の整合性が取れた動画を出しやすくなっています。動画生成モデル単体では難しかった「文脈に正しい絵作り」が期待できます。
主要機能まとめ
Omni Flashで現在使える機能を整理します。
Text/Image to Video
リファレンス画像とテキスト指示を渡すと、10秒程度の音声付きクリップを生成します。短尺ですが、SNS用素材としては十分使える長さです。
Video Editing
既存動画に対してチャット指示で編集できます。代表的な編集操作はこのあたりです。
- キャラクターの差し替え
- ライティング調整
- 手ぶれ補正(スタビライズ)
- 背景の差し替え
これらをコマ単位の編集ソフトを開かずに自然言語だけで完結できるのが新しい体験です。
Avatar Mode
自分の顔と声をスキャンしてデジタル分身を作る機能です。
- 顔登録 フロントカメラで複数角度を撮影
- 音声登録 提示された数字とフレーズを読み上げる
- セットアップ時間 約2分
- 制約 18歳以上限定、本人のみが登録可能
ディープフェイク対策として、第三者の顔や声を勝手にアバター化できない設計になっています。
SynthIDウォーターマーク
Omniが生成したすべての動画には、不可視のSynthIDデジタルウォーターマークが自動で埋め込まれます。
- 視聴者には見えない
- Geminiアプリ、Gemini in Chrome、Google Searchで真正性を検証可能
- API経由でも無効化できない仕様
合成メディア時代の検証可能性を担保するための重要な仕組みです。
法人向け生成AIサービス「ナレフルチャット」では、ChatGPT、Gemini、Claudeなど主要プロバイダのAIモデルを選んで利用可能!用途に応じて、料金の低いモデルを使うなど最適なAI活用を可能にします。
また、料金プランは企業単位の定額制を採用しており、何人で利用しても追加のコストは発生しないため、コスト管理の手間がかからないスムーズな全社導入を実現できます。
初月無料で生成AIが利用できるトライアル期間も用意しておりますので、生成AIの利活用を検討している企業様は、是非一度導入をご検討ください。実際に触ってみた
ここからは「Omniのどんな能力を試したら一番面白いか」を考えて、3つの検証パターンを用意しました。それぞれOmniの個性が出る切り口になっています。各パターンに本記事で実際に投げるプロンプトをセットで載せています。
検証環境
- 利用チャネル Google Flow
検証パターン1 物理理解チャレンジ
Omniが世界モデルとして持つ物理エンジンの精度を試すケースです。重力・衝突・破壊といった瞬間的な物理現象は、過去の動画生成モデルがもっとも苦手としてきた領域。Omniがどこまで「らしい挙動」を再現できるかを見ていきます。
プロンプト
赤ワインで満たされたクリスタルのワイングラスが、大理石のキッチンカウンター
の端から滑り落ちる。落下中にグラスは時計回りにゆっくり回転し、ボウル部分
から大理石の床に衝突。接触の瞬間、グラスは放射状に砕け、鋭利なガラス片が
四方へ飛散する。中の赤ワインは慣性で前方に飛び出し、扇状に広がりながら
細かな飛沫を生む。着地したワインは大理石の目地に沿って枝分かれしながら
じわじわ広がっていく。1000fps相当のスーパースローモーション、床面すれすれ
の真横ローアングル、朝の窓から差し込む斜光がガラス片と液滴に屈折し、床に
プリズム状の光斑を描く。被写界深度浅め、シネマティック。4秒。
画像はワンシーンの抜粋です。動画の全編をFlowで再生する
考察
正直に言って、予想以上の手応えでした。グラスの回転と落下軌道、放射状の破砕パターン、慣性で前方に飛び出すワインの動きまで、過去モデルにありがちな「破片が宙に浮く」「破壊の起点が曖昧」といった違和感がほぼ抑えられています。
細かく見るとまだ詰めたい部分はありますが、ひとつのプロンプトだけでここまでリアルなシーンが出てくるのは本当に驚きでした🐰
検証パターン2 キャラクター入れ替え
公式の動画生成ページでも推されている「人物の入れ替え」を試します。元動画に映っている人物を、まったく別のキャラクターに差し替えても、動作・小道具・背景・カメラワークが保たれるかを見る検証です。Omniならではの面白い使い方になります。
3ステップに分けて検証してみました。
Step1 元動画をGrokで生成
まずは入れ替え元になる動画を、別ツールのGrokで生成しておきます。今回は1880年代の西部劇シーンを選びました。
A rugged cowboy pushes open saloon doors and steps into smoky amber
lamplight. Piano plays in the background. He scans the room slowly.
Medium shot tracking in. Whiskey glass on the bar. Shadows cut hard
across his face. 1880s frontier. Noir western mood.
画像はワンシーンの抜粋です。動画の全編をGrokで再生する
Step2 入れ替え用キャラクターをFlowで生成
次に、入れ替え後に登場させたいキャラクターをGoogle Flow上で生成します。これがOmniに渡すリファレンスになります。
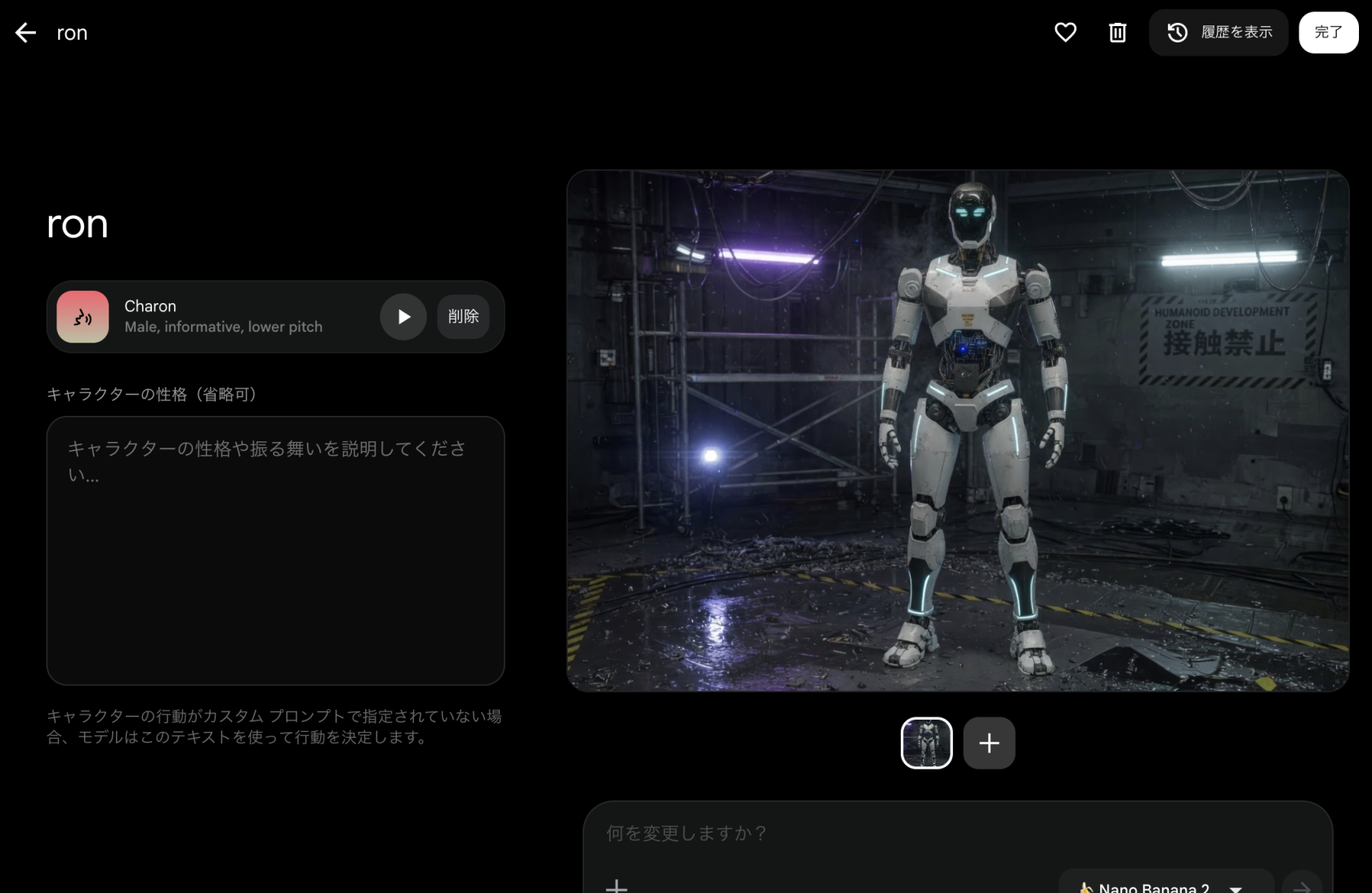
Step3 Omniで人物を入れ替え
Step1の元動画とStep2のキャラクターをOmniに渡し、人物の入れ替えを実行します。背景のサルーン、カメラの動き、照明はそのままに、主役だけを差し替えるイメージです。

画像はワンシーンの抜粋です。動画の全編をFlowで再生する
おまけ あとから任意のキャラクターを追加
人物の入れ替えだけでなく、シーンに新しいキャラクターを後から足すのもプロンプト1つで完結します。試しに主人公の横にダチョウを並べてもらったところ、サルーンの世界観を保ったまま自然に追加できました。

画像はワンシーンの抜粋です。動画の全編をFlowで再生する
考察
環境側の引き継ぎ精度は想像以上です。サルーンの木製カウンター、ウィスキーグラス、アンバー色のランプ照明がほぼ忠実に残り、カメラのトラッキング動作も維持。扉を押し開ける動作と「室内を見回す視線」の流れまで新キャラに転写されているのが印象的でした。
気になる点としては、体格差による扉と肩の接触点のわずかな浮きや、衣装と1880年代西部劇の世界観のミスマッチなど。とはいえ「環境+カメラワーク+動作」を保ったまま主役だけ差し替えるという、編集ソフトで何時間もかかる作業がワンプロンプトで叩き台レベルまで仕上がるのは大きい体験でした🐰
検証パターン3 マルチモーダル合成(画像+音声+テキスト)
ネイティブマルチモーダルの真価を確かめる検証です。手元の製品画像、雰囲気の参考画像、声のサンプル、そしてテキスト指示をすべて同時に渡し、Omniが情報を束ねて1本の動画に落とし込めるかを見ます。
3ステップに分けて検証してみました。
Step1 参考画像をnanobananaで2枚生成
元素材となる2枚の画像をnanobananaで作成します。製品写真の方は検証用に「MORI COFFEE」のオリジナルロゴと帯デザインを入れ、Omniがロゴや文字をどこまで保持できるかも一緒に見られるようにしました。
画像A 製品写真(マグカップ単体、白背景)

画像B 早朝の森のアンビエンス写真

Step2 Omniに入力セットを渡す
Step1の2枚の画像と、ナレーション音声、そしてテキストプロンプトをまとめてOmniに渡します。ナレーションは別途Grokで生成した下記の動画を素材として利用しました。
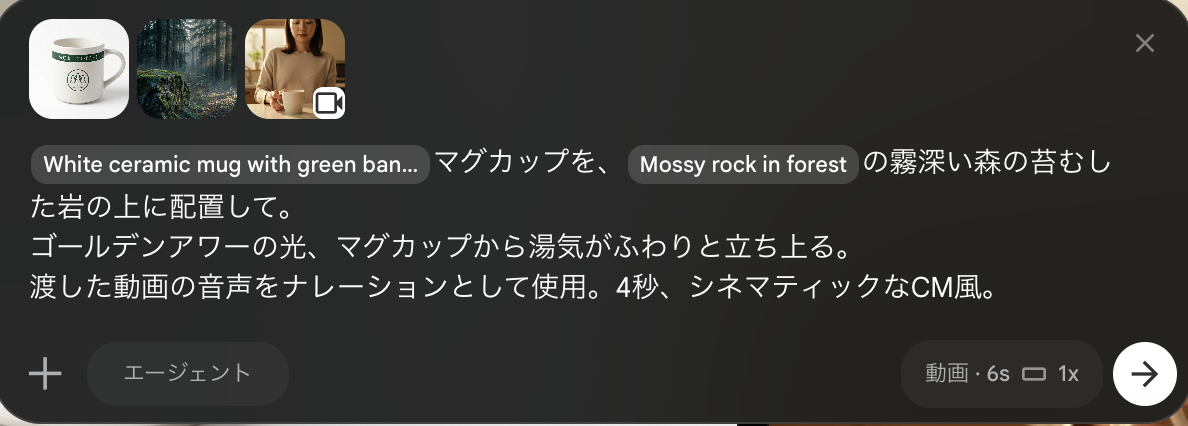
[プロンプト]
画像Aのマグカップを、画像Bの霧深い森の苔むした岩の上に配置して。
ゴールデンアワーの光、マグカップから湯気がふわりと立ち上る。
渡した動画の音声をナレーションとして使用。4秒、シネマティックなCM風。Step3 Omniで動画生成
入力セットを束ねてOmniが生成した動画がこちらです。

画像はワンシーンの抜粋です。動画の全編をFlowで再生する
考察
画像A・画像B・外部音声・テキストという4つの素材を同時に渡しても、Omniは各要素を1本のCM風動画にまとめてくれました。製品の質感、森の空気感、ゴールデンアワーの光、そしてナレーションがひとつのプロンプトで重なる体験は新鮮です。
ロゴや文字の細部、湯気の自然さなど詰めたい部分はあるものの、これまで撮影・素材集め・編集と複数工程を跨いでいたCM制作の叩き台が、Omni1本でほぼ完結するインパクトを感じました🐰
検証総括
3つの検証を通して見えてきたOmniの手触りをまとめます。
良かったところ
- 物理現象の自然さ(落下軌道・破砕パターン・液体の慣性)が想像以上にしっかり描かれる
- キャラクター入れ替えで「環境+カメラワーク+動作」が忠実に引き継がれる
- 画像+音声+テキストを束ねたマルチモーダル合成がワンプロンプトで成立する
- 短尺の中でもシネマティックな絵作りが安定して出てくる
気になったところ
- 超ハイスピード演出など、極端な指示の細部はまだ均質化されがち
- リファレンスのスタイルと出力世界観のミスマッチは手動で詰める必要がある
- ロゴ・文字といった「細かい記号情報」の保持は今後の改善余地あり
一番面白かった検証パターン
うさぎ的にハマったのは検証パターン3のマルチモーダル合成でした。複数の素材を束ねてひとつのストーリーに昇華する体験はOmniならではで、CM・ショート動画制作のワークフローを本気で変えてくる予感があります🐰
まとめ
Gemini Omniはテキスト・画像・音声・動画をひとつのモデルで束ねて扱うネイティブマルチモーダルモデルです。ポイントを最後にもう一度整理しておきます。
- ネイティブマルチモーダルで任意の入力組み合わせから音声付き動画を生成
- 物理法則を理解した世界モデルで違和感の少ないシーンを作れる
- 会話形式のマルチターン編集が他社モデルにない独自の体験
- アバター機能とSynthIDウォーターマークで責任あるロールアウトに対応
- 現状はGeminiアプリとGoogle Flowから利用可能、APIは数週間以内に開放予定
API開放やOmni Pro登場のタイミングも引き続きウォッチしていきます。まずは触って手触りを掴んでおくのがおすすめうさよ🐰
あなたも生成AIの活用、始めてみませんか?
生成AIを使った業務効率化を、今すぐ始めるなら
「初月基本料0円」「ユーザ数無制限」のナレフルチャット!
生成AIの利用方法を学べる「公式動画」や、「プロンプトの自動生成機能」を使えば
知識ゼロの状態からでも、スムーズに生成AIの活用を始められます。
taku_sid
https://x.com/taku_sid
AIエージェントマネジメント事務所「r488it」を創立し、うさぎエージェントをはじめとする新世代のタレントマネジメント事業を展開。AI技術とクリエイティブ表現の新たな可能性を探求しながら、次世代のエンターテインメント産業の構築に取り組んでいます。
ブログでは一つのテーマから多角的な視点を展開し、読者に新しい発見と気づきを提供するアプローチで、テックブログやコンテンツ制作に取り組んでいます。「知りたい」という人間の本能的な衝動を大切にし、技術の進歩を身近で親しみやすいものとして伝えることをミッションとしています。








スマートフォンでもAI活用!
アプリ版「ナレフルチャット」配信中
iPhoneはこちら


Androidはこちら




