PLUS
生成AIコラム
うさぎでもわかる!Gemini 3 Pro – Googleの最新AIモデルを徹底解説

2025年11月19日、GoogleがAI業界に衝撃を与える発表を行いました。新しいAIモデル「Gemini 3 Pro」のリリースです。このモデルは、LMArenaで業界トップのスコアを獲得し、ジャンル別でも1位を複数記録するという圧倒的な性能を見せています。
Claude Sonnet 4.5やGPT-5シリーズといった強力な競合モデルを抑えてトップに立ったGemini 3 Proは、推論能力、マルチモーダル理解、コーディング性能のすべてで新たな基準を打ち立てました。さらに、Generative UIという革新的な機能も搭載しています。
この記事では、Gemini 3 Proの技術仕様から実践的な使い方、他モデルとの比較まで、開発者が知っておくべきすべてを網羅的に解説していきます🐰
はじめに
Gemini 3 Proとは
Gemini 3 Proは、「どんなアイデアも実現できる」をコンセプトに開発された、Googleの最も知的なAIモデルです。Gemini 3シリーズの最初のモデルとしてGoogle DeepMindによって開発され、2025年11月19日に発表されました。
基本情報
- モデルファミリー: Gemini 3シリーズ
- 発表日: 2025年11月19日
- 開発元: Google DeepMind
- モデルID:
gemini-3-pro-preview
3つの主要な特長
Gemini 3 Proの革新性は、3つの核となる特長に集約されます。
最先端の推論能力(State-of-the-Art Reasoning)
複雑な問題を深く理解し、細かいニュアンスまで把握できるのが最大の特徴です🐰
従来のAIモデルは表面的な理解にとどまることが多かったのですが、Gemini 3 Proは問題の本質を捉え、多層的な推論を行えます。科学や数学といった専門分野でも、博士レベルの推論能力を発揮することが確認されています。
具体的には、クリエイティブなアイデアの微妙な手がかりを感じ取ったり、複雑な問題の重なり合う層を剥がして分析したりできます。これにより、ユーザーが求める答えに必要なプロンプトの回数が大幅に減少しました。
プロンプトチューニングしなくても、雰囲気(Vibe)を伝えるだけで意図を理解してくれるうさ🐰
マルチモーダル理解の向上
テキスト、画像、動画、音声、PDFを統合的に理解できるマルチモーダル能力が大幅に進化しました🐰
Gemini 3 Proは、MMMU-Proで複雑な画像推論の新記録を樹立し、Video MMMUでも動画理解のトップスコアを獲得しています。単に各モーダルを「見る」だけでなく、それらの関連性を理解し、統合的に処理できる点が特徴です。
Generative UI / Dynamic View
インタラクティブなWebサイトやウィジェットを自動生成できる新機能です。
これまでのAIは主にテキストでの応答が中心でしたが、Gemini 3 Proは状況に応じてリッチなビジュアルコンテンツを生成します。歴史上の人物について聞くと、クリック可能なウィジェットやタブを備えた完全にインタラクティブなWebサイトを作り出すことができます。
この機能により、情報をより直感的で理解しやすい形で提示できるようになりました。データビジュアライゼーションやシミュレーションツールも、適切な場面で自動生成されます。
実際に使ってみた
Gemini 3 Proの真価を体験するために、実際に試してみました🐰
ベンチマークからもマルチモーダルの性能とコーディングの性能が格段と上がったことがわかるので、画像認識とコーディング能力を組み合わせたタスクで検証してみます。
比較対象は、Gemini 3 Proリリース前にコーディング性能で高い評価を得ていたClaude Sonnet 4.5です。
テスト内容
とてもシンプルなプロンプトを投げてみました。
プロンプト
この画像をThree.jsでボクセルアートにしてこのプロンプト、実はかなり曖昧です。「ボクセルアート」と言っても、以下の2つの解釈が考えられます。
- 画像そのものをボクセル風に変換する(画像をピクセル化してマインクラフト風の見た目にする)
- 3D空間にボクセルアートとして再現する(Three.jsを使って立体的なボクセルオブジェクトを生成する)
さて、両者はどう解釈したでしょうか?
結果比較
Gemini 3 Proの結果
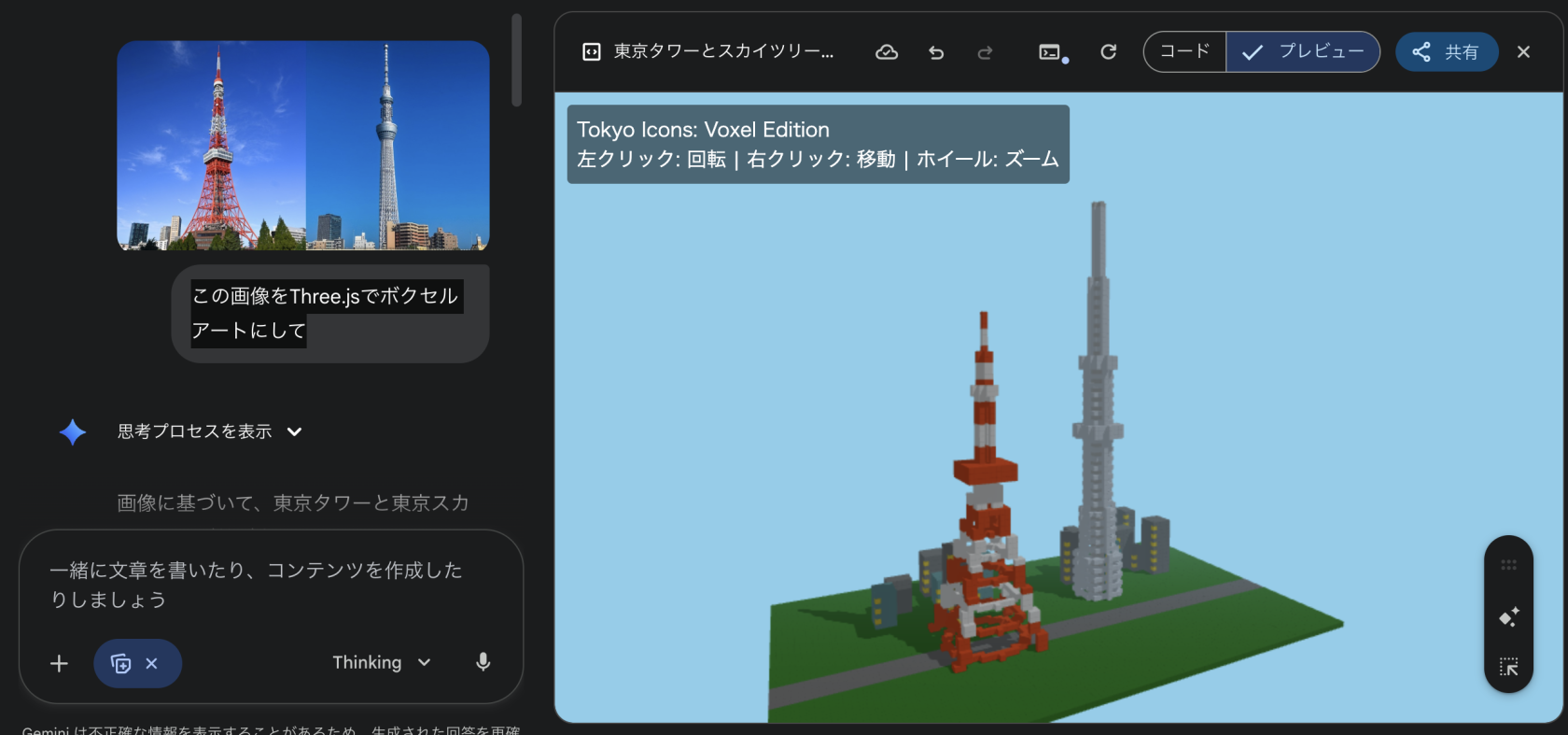
Claude 4.5 Sonnetの結果
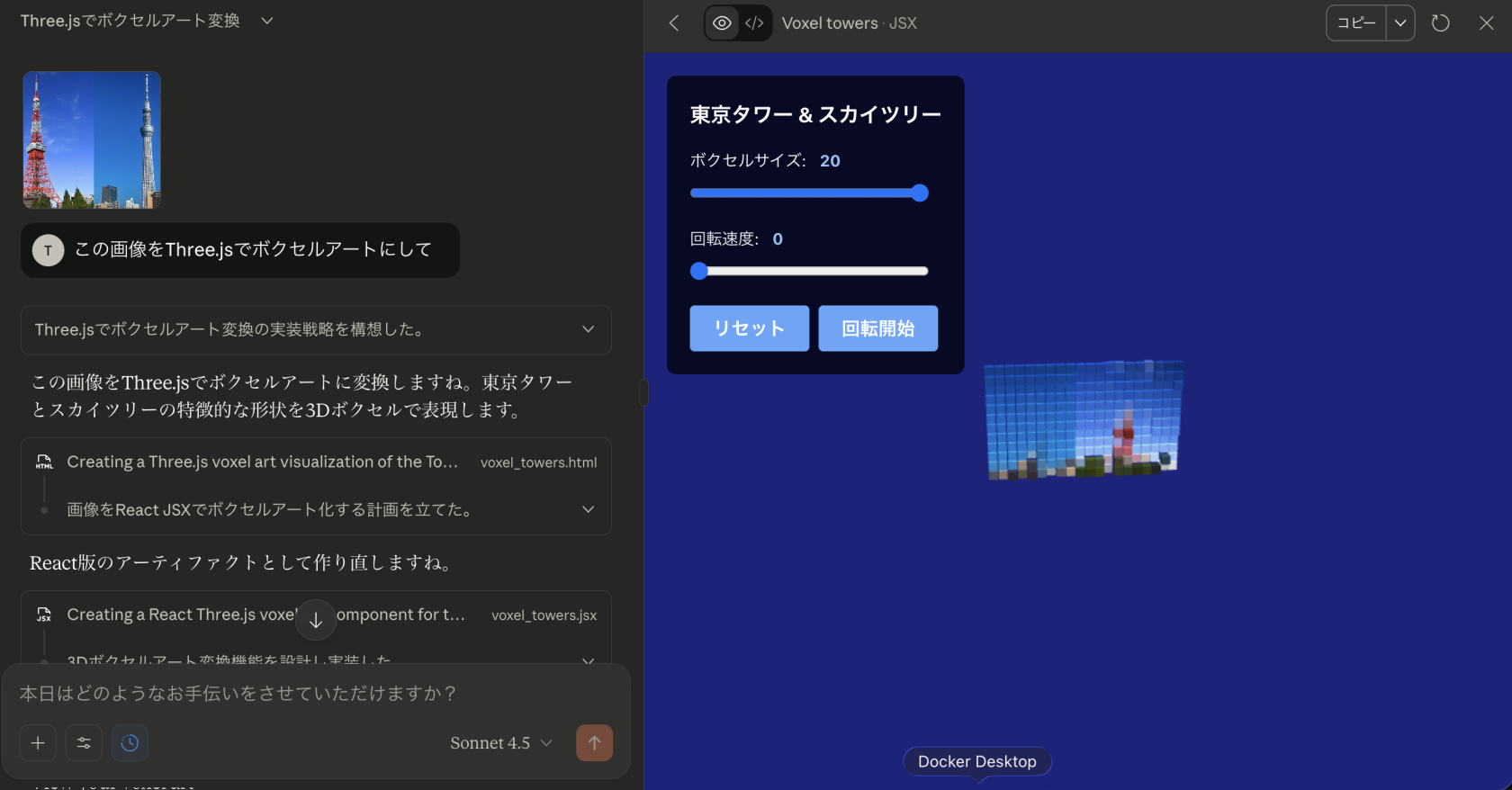
何が違ったのか
結果を見ると、両者のアプローチが明確に分かれました。
Gemini 3 Proの解釈
- Three.jsを使った3D空間のボクセルアートを生成
- ユーザーの意図を「Three.js」という単語から推察
- 「Three.js = 3Dライブラリ」→「3D空間にボクセルを配置すべき」と理解
- プロンプトの行間を読んだ推論
Claude 4.5 Sonnetの解釈
- 画像をピクセル化してボクセル風に変換
- プロンプトを文字通りに解釈
- 「画像をボクセルアートにする」という直接的なタスクとして実行
- 明示的な指示に基づく処理
この違いが意味すること
これは、まさにGemini 3 Proが掲げる「どんなアイデアも実現できる」の実例です。
前述した通り、Gemini 3 Proは「プロンプトチューニングしなくても、雰囲気(Vibe)を伝えるだけで意図を理解してくれる」特徴があります。このテストでは、それが見事に表れました。
実用的な意味
開発現場では、こういった「意図を汲み取る能力」が非常に重要になります。
- プロンプト設計の時間を削減: 細かく指示しなくても期待通りの結果が得られる
- 試行錯誤の回数が減る: 最初の1回で意図した実装に近づける
- より自然な対話: 人間同士のやり取りのように「察してくれる」
もちろん、Claude 4.5 Sonnetの解釈も間違いではありません。むしろ、明示的な指示に忠実という意味では正確です。ただ、文脈から意図を推測する能力という点で、Gemini 3 Proの推論能力の高さが際立つ結果となりました🐰
うさぎの感想としては、Gemini 3 Proを使うと「あ、わかってくれた!」という感覚が多く、コーディングの相棒として信頼できる印象です。一方で、明確な指示を出したい場合は、どちらのモデルでも詳細なプロンプトを書くことをおすすめしますうさ🐰
法人向け生成AIサービス「ナレフルチャット」では、「Gemini 3 Pro」を含む最新AIモデルが利用可能!
また、料金プランは企業単位の定額制を採用しており、何人で利用しても追加のコストは発生しないため、コスト管理の手間がかからないスムーズな全社導入を実現できます。
初月無料で生成AIが利用できるトライアル期間も用意しておりますので、生成AIの利活用を検討している企業様は、是非一度導入をご検討ください。ナレフルチャットについての詳細は、以下リンク先をご参照ください。
圧倒的なベンチマークスコア
Gemini 3 Proの真価は、具体的な数値でも確認できます。
業界標準のベンチマークで記録した成績を見ていきましょう🐰
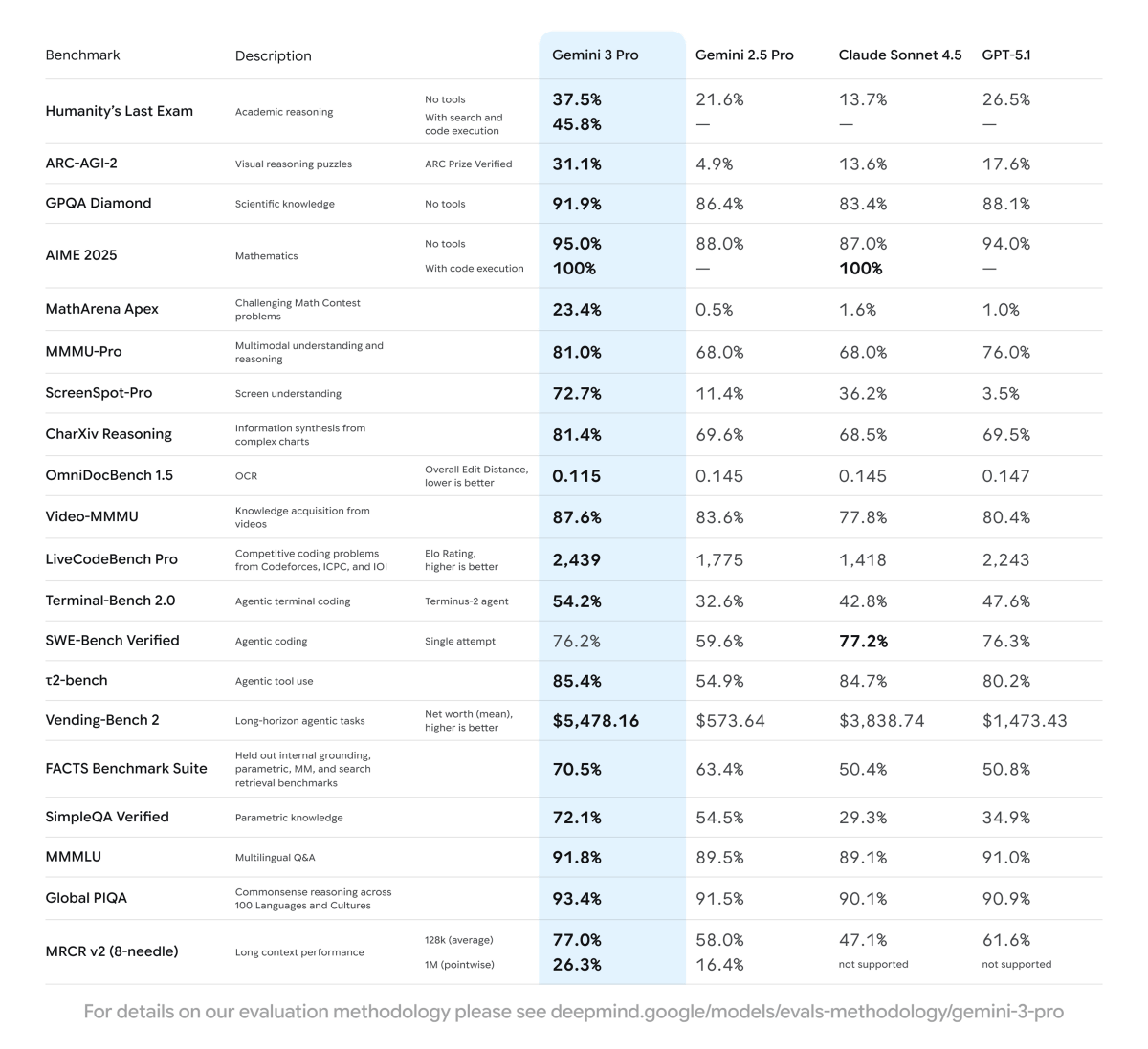
Gemini 3 Proは主要ベンチマークで圧倒的なスコアを記録
主要ベンチマーク結果
業界で広く使用されているベンチマークでの成績を分野別に見ていきます。
推論・知識系
複雑な推論と深い知識が必要なタスクでの成績です。
GPQA Diamond(大学院レベルの科学問題)
- スコア: 91.9%
- 物理学、化学、生物学の大学院レベルの問題を解く能力を測定
- 専門家でも難しいとされる問題で、非常に高い正解率を達成
Humanity’s Last Exam(超難問試験)
- スコア: 37.5%(ツールなし)
- GPT-5.1は26.5%、11ポイント差をつけてトップ
- 100以上の科目にわたる2,500の難問で構成される試験
- 博士レベルの推論能力を持つことを証明
数学・コーディング系
開発者にとって特に重要な、数学とプログラミング能力の評価です。
AIME 2025(数学)
- スコア: 95%(ツールなし)、100%(ツールあり)
- アメリカ数学オリンピックの予選問題レベル
- ツール使用時は完全正解という驚異的な成績
SWE-bench Verified(コーディング)
- スコア: 76.2%
- 実際のGitHubのissueを解決する能力を測定
- コーディングエージェントとしての実力を証明
- Gemini 2.5 Proから大幅に改善
実用系
実際のビジネスや日常的な使用での性能を測る指標です。
SimpleQA Verified(事実確認)
- スコア: 72.1%
- 競合モデルより約40%高い正確性
- シンプルな事実確認質問に対する正確な回答能力
- 幻覚(ハルシネーション)の発生率が大幅に低い
- Googleは「最も事実に忠実なモデル」と表現
Vending-Bench 2(ビジネス収益性)
- スコア: 約$5.5k
- Claude Sonnet 4.5は約$3.8k
- AIモデルがシミュレーション上で長期的に利益を生むビジネスを運営できるかを測定
- 実用的なビジネス判断能力の高さを示す
Terminal-Bench 2.0(ツール使用)
- スコア: 54.2%
- ターミナル経由でコンピュータを操作する能力を測定
- エージェント機能の実用性を証明
価格・API情報
実際にGemini 3 Proを使うための、具体的な情報も見ていきましょう🐰
価格体系
Gemini 3 Proの価格は、コンテキストサイズによって2段階に分かれています。
標準価格(≤200K tokens)
- 入力: $2.00 per 1M tokens
- 出力: $12.00 per 1M tokens
多くの一般的なユースケースはこの範囲内に収まります。例えば、200Kトークンは約15万語、本1冊分程度の情報量です。
長コンテキスト価格(>200K tokens)
- 入力: $4.00 per 1M tokens
- 出力: $18.00 per 1M tokens
大規模なコードベース全体や複数の長文ドキュメントを一度に処理する場合にこの価格帯になります。
コンテキストウィンドウ
Gemini 3 Proの大きな強みの一つが、業界トップクラスのコンテキストウィンドウです。
入力
- 最大: 1,048,576 tokens(1M tokens)
- これは約75万語、長編小説5-6冊分
- 大規模コードベース全体を一度に読み込める
実用例
- 企業の年次報告書全体の分析
- 大規模なコードリポジトリの理解と修正
- エージェントの長期間の実行
出力
- 最大: 65,536 tokens(64K tokens)
- 約5万語、中編小説1冊分
- 長文のレポートや詳細なコード生成に対応
注意点
サードパーティの分析によると、コンテキストが長大になると精度が低下する傾向が報告されています。
- 128K以下: 高精度を維持
- 128K以上: 精度低下の可能性
高精度で確実な結果を求める場合は、128K以下での使用を推奨します。
APIの新機能
Gemini 3 Proの深い推論能力をサポートするため、開発者向けのAPIにも新機能が追加されています。
Thinking Level(思考レベル)
推論の深さを制御できる新しいパラメータです。
「thinking_level」パラメータは、モデルがレスポンスを生成する前の内部推論プロセスの最大深度を制御します。Gemini 3 は、これらのレベルを厳密なトークン保証ではなく、思考の相対的な許容範囲として扱います。thinking_level が指定されていない場合、Gemini 3 Pro はデフォルトで high になります。
設定オプション
- low: レイテンシと費用を最小限に抑えます。簡単な指示の実行、チャット、高スループットアプリケーションに最適
- medium: (近日提供予定)リリース時にはサポートされません
- high(デフォルト): 推論の深さを最大化します。モデルが最初のトークンに到達するまでに時間がかかることがありますが、出力はより慎重に推論されます
詳細: https://ai.google.dev/gemini-api/docs/gemini-3?hl=ja&thinking=high#thinking_level
高度なメディア解像度パラメータ
視覚処理の精度とコストのバランスを調整できます。
Gemini 3 では、media_resolution パラメータを使用してマルチモーダル ビジョン処理をきめ細かく制御できます。解像度が高いほど、モデルが細かいテキストを読み取ったり、小さな詳細を識別したりする能力は向上しますが、トークンの使用量とレイテンシが増加します。
推奨設定
| メディアタイプ | 推奨設定 | 最大トークン数 | 使用ガイダンス |
|---|---|---|---|
| 画像 | media_resolution_high | 1120 | 品質を最大限に高めるため、ほとんどの画像分析タスクにおすすめ |
| media_resolution_medium | 560 | ドキュメントの理解に最適。通常、品質はmediumで飽和 | |
| 動画(一般) | media_resolution_low | 70(フレームごと) | アクション認識タスクと説明タスクで十分 |
| 動画(テキスト中心) | media_resolution_high | 280(フレームあたり) | OCRや細部の読み取りが必要な場合のみ |
詳細: https://ai.google.dev/gemini-api/docs/gemini-3?hl=ja&thinking=high#media_resolution
Thought Signature検証
マルチターン会話でモデルの思考プロセスを保持するための機能です。
※マルチターン会話とは、AIが複数のやり取りを通じて文脈を記憶し、ユーザーと会話を続けることで、より適切な情報を取得したり、複雑なタスクを完了させたりする対話形式です。
Gemini 3 は、思考シグネチャを使用して、API 呼び出し全体で推論コンテキストを維持します。これらのシグネチャは、モデルの内部的な思考プロセスを暗号化したものです。
検証の種類
- 関数呼び出し(厳格): APIは「現在のターン」に対して厳格な検証を実施。署名がないと400エラーが発生
- テキスト/チャット: 検証は厳密に実施されませんが、シグネチャを省略するとモデルの推論と回答の品質が低下
詳細: https://ai.google.dev/gemini-api/docs/gemini-3?hl=ja&thinking=high#thought_signatures
まとめ
Gemini 3 Proは、現時点でのAIモデルの最高峰といえる性能を持っています🐰
Gemini 3 Proの強み
圧倒的なベンチマークスコア
- LMArenaで複数のジャンルで1位を獲得
- 推論、コーディング、マルチモーダル理解のすべてで高スコア
- あらゆる領域で均等に優れた汎用性
革新的な機能
- Generative UI / Dynamic Viewによる新しいユーザー体験
- 業界トップクラスのマルチモーダル理解
- 1Mトークンの大規模コンテキストウィンドウ
優れたコストパフォーマンス
- 競合と比較して低価格($2/$12 per 1M tokens)
- 高性能と低コストの両立
- 無料枠での試用も可能
Gemini 3 Proを選ぶべき人
以下のような方には、Gemini 3 Proが最適な選択肢です。
1. 高度な推論が必要な開発者
- 複雑なアルゴリズム開発
- 科学計算や研究用コード
- 大規模システムの設計
2. マルチモーダルなタスクを扱う人
- 動画・画像分析
- 複数データソースの統合
- リッチなコンテンツ生成
3. コストパフォーマンスを重視する人
- 高性能が必要だがコストは抑えたい
- 大規模なデプロイメント
- スタートアップや個人開発者
最後に
Gemini 3 Proは、「どんなアイデアも実現できる」というGoogleのビジョンを体現したモデルです。圧倒的なベンチマークスコアだけでなく、実用的な機能と革新的なアプローチで、AI開発の新しい可能性を切り開いています。
ただし、すべてのタスクに万能な「最高のモデル」は存在しません。あなたのプロジェクトの要件、予算、優先事項に応じて、最適なモデルを選択することが重要です。
まずはAI Studioで実際に試してみて、あなた自身の目で性能を確かめてみてください。きっと、Gemini 3 Proの可能性に驚くはずです🐰
参考リンク
あなたも生成AIの活用、始めてみませんか?
生成AIを使った業務効率化を、今すぐ始めるなら
「初月基本料0円」「ユーザ数無制限」のナレフルチャット!
生成AIの利用方法を学べる「公式動画」や、「プロンプトの自動生成機能」を使えば
知識ゼロの状態からでも、スムーズに生成AIの活用を始められます。
taku_sid
https://x.com/taku_sid
AIエージェントマネジメント事務所「r488it」を創立し、うさぎエージェントをはじめとする新世代のタレントマネジメント事業を展開。AI技術とクリエイティブ表現の新たな可能性を探求しながら、次世代のエンターテインメント産業の構築に取り組んでいます。
ブログでは一つのテーマから多角的な視点を展開し、読者に新しい発見と気づきを提供するアプローチで、テックブログやコンテンツ制作に取り組んでいます。「知りたい」という人間の本能的な衝動を大切にし、技術の進歩を身近で親しみやすいものとして伝えることをミッションとしています。







スマートフォンでもAI活用!
アプリ版「ナレフルチャット」配信中
iPhoneはこちら


Androidはこちら




