PLUS
生成AIコラム
うさぎでもわかる!ローカルLLM比較ガイド 注目モデルの実力と使い分け

目次:
はじめに
「え、スマホでAIが動くの?」── 2026年、この驚きを体験する人が急増しています。
Gemma 4はスマホで秒速50トークンを叩き出し、Kimi K2.5はGPT-5.2やClaude Opus 4.5を一部ベンチマークで上回る。もう「ローカルLLM=精度が低い」は完全に過去の話です。
この記事では、2026年4月時点のローカルLLM事情をまるっと整理します。
- ローカルLLMの基礎(オープンソースとオープンウェイトの違いも)
- Kimi K2.5やGemma 4など注目モデルの実力比較
- ChatGPT・Gemini・Claudeとの賢い使い分け方
- AI Edge Galleryを使った実機検証の結果
「API課金がじわじわツラい」「社内データをクラウドに送りたくない」── そんな悩みを持つ方にこそ読んでほしい内容です。もちろん、純粋に「最新のAI事情が気になる!」という方も大歓迎🐰
生成AIの社内利用をお考えの企業様へ
ナレフルチャットはPCでもスマートフォンでも使えるマルチデバイス対応だから、オフィスでも外出先でもAIをすぐに呼び出せます。初心者でも使いやすい設計で、プロンプト自動生成機能や社内共有機能により、AIリテラシーに差があっても場所やデバイスを選ばず全員が活用できます。
企業のAI導入を検討している方は、こちらをご覧ください。ローカルLLMの基礎知識
まずはローカルLLMとオープンソース/オープンウェイトの違いをサクッと押さえるうさ🐰
ローカルLLMとは
ローカルLLMとは、自分のPC・スマホ・サーバー上でAIモデルを直接動かす仕組みのことです。ChatGPTやGeminiのようにクラウドにデータを送る必要がなく、すべてが手元で完結します。
| 項目 | クラウド型(ChatGPT等) | ローカルLLM |
|---|---|---|
| データの送信先 | 外部サーバー | 自分のデバイス内で完結 |
| インターネット | 必須 | 不要(オフライン動作可) |
| コスト | API従量課金 | 初期投資のみ(GPU等) |
| カスタマイズ | サービス依存 | ファインチューニング自由 |
| プライバシー | △(データ送信あり) | ◎(データが外に出ない) |
なぜ2026年にローカルLLMが注目されているのか
ひとことで言えば、「使わない理由」がなくなってきたからです。
- 性能がプロプライエタリモデルに追いついた ── Kimi K2.5はHumanity’s Last Examで商用モデルを上回るスコアを記録。もう「クラウドの方が賢い」とは一概に言えない
- スマホで動くモデルが登場 ── Gemma 4 E2BはLiteRTの2bit/4bit量子化により1.5GB未満のメモリで動作。特別なハードウェアがなくてもAIを手元で動かせる
- データ機密性とコストの両立 ── 医療・金融データなど外部に出せないデータの処理、大量バッチ処理でのAPI代の節約。使えば使うほどローカルが有利になる構造
オープンソース vs オープンウェイト ── 似ているけど結構違う
「オープンソースLLM」と呼ばれるモデル、じつは大半がオープンウェイトです。ビジネスでの採用を考えるなら、この違いは知っておきたいポイントです。
- オープンソース = ソースコード+学習データ+学習手順まで全公開
- 代表例はOLMo 2(Allen AI)。完全な再現性があり、研究者がゼロから再学習できる
- オープンウェイト = モデルの重み(パラメータ)のみ公開。学習データや手順は非公開
- Llama 4、Kimi K2.5、GPT-OSS、Gemma 4はすべてこちら。推論やファインチューニングは自由だが、ゼロからの再学習はできない
実務で使う分にはオープンウェイトで十分なケースがほとんどです。大事なのはむしろ「ライセンス」の方。商用利用の条件をしっかり確認しましょう🐰
2026年のトレンドとして、Apache 2.0ライセンスへの移行が加速しています。Gemma 4もGemma 3までの独自ライセンスからApache 2.0に変更。Qwen、Mistral、GPT-OSSもApache 2.0。企業が法務チェックの手間なく導入できる環境が整ってきました。
2026年注目モデル比較と商用モデルとの使い分け
ローカルLLMと商用APIは競合じゃなくて補完関係。用途で選ぶのが正解だうさ🐰
フロンティア級 ── 商用モデルを脅かす超大規模オープンモデル
2026年のオープンモデルは、MoE(Mixture of Experts) アーキテクチャが主流になりました。全パラメータを常に使うのではなく、入力に応じて一部の「専門家」だけを起動する設計です。1兆パラメータの巨大モデルでも、実際に動くのは数十Bだけ── だから効率的に推論できるわけです。
| モデル | 総パラメータ | アクティブ | ライセンス | ここがスゴい |
|---|---|---|---|---|
| Kimi K2.5 | 1T(MoE) | 32B | オープンウェイト | 最大100サブエージェントを並列起動する「Agent Swarm」。マルチモーダル対応 |
| Qwen 3.5 | 397B(MoE) | 17B | Apache 2.0 | アクティブ17Bで驚異的コスパ。VLM対応で画像も理解 |
| DeepSeek V3.2 | 671B(MoE) | 37B | MIT | 200〜300回のツール連続呼び出しが可能。エージェント用途に最強 |
Kimi K2.5(Moonshot AI、2026年1月リリース)は特に注目すべきモデルです。1兆パラメータのMoEアーキテクチャで、ツール使用時のHumanity’s Last Exam(HLE)で50.2%を記録。これはClaude Opus 4.5の43.2%、GPT-5.2の45.5%を上回る数値です。
ただし、1Tモデルをローカルで動かすにはH100クラスのGPUが複数台必要です。個人で使うなら、APIを利用するのが現実的でしょう。
実用サイズ ── あなたのゲーミングPCで動くモデルたち
ここが一番ホットなゾーンです。RTX 4090やMac Studio M4があれば、かなり賢いモデルを手元で動かせます。
| モデル | パラメータ | ライセンス | 注目ポイント |
|---|---|---|---|
| Gemma 4 31B | 31B Dense | Apache 2.0 | テキスト・画像・音声・動画すべて対応。 |
| Gemma 4 26B MoE | 26B(実稼働3.8B) | Apache 2.0 | 実稼働3.8Bだから軽い。 |
| Qwen3.5 4B/9B | 4B / 9B | Apache 2.0 | ゲーミングPCで余裕。VLM対応でコスパ最強 |
| GPT-OSS 21B | 21B(実稼働3.6B) | Apache 2.0 | あのOpenAIが出した初のオープンウェイト |
| GLM-4.7-Flash | 30B-A3B(MoE) | MIT | MoEで軽量かつ高速。サクサク動く |
| Nemotron 3 Nano | 30B-A3B(MoE) | NVIDIA OML | Mamba-2+MoE+Attentionのハイブリッド構造。 |
「とりあえず最初の1つ」ならGemma 4 26B MoEがおすすめです。実稼働わずか3.8Bなのにリリース時Arenaオープンモデル6位を記録した実力、Apache 2.0で商用もOK、テキスト・画像・音声・動画すべて対応。16GB程度のVRAMがあれば快適に動きます。もう少し軽くしたいならE4B(約3.7GB)でスマホでも動きます🐰
商用モデルとの使い分け ── 「どっちが上」ではなく「どう組み合わせるか」
ローカルLLMと商用モデル(ChatGPT、Gemini、Claude)は、競合ではなく補完関係です。
商用APIを選ぶべきとき
- 最高精度がほしい(論文解析、複雑な推論、長文分析)
- 400K+トークンの長いコンテキストが必要
- 安定したSLAが求められる本番サービス
- チームで統一的な環境を使いたい
ローカルLLMを選ぶべきとき
- 機密データを外部に出せない(医療、金融、社内情報)
- 大量バッチ処理でAPI代を節約したい
- オフライン環境で使いたい(出張先、セキュアな施設内)
- ファインチューニングで自社特化させたい
両方使う「ハイブリッド」がベスト
- 日常的なコード補完はローカル、複雑なリファクタは商用API
- RAG構築で埋め込みとチャンクはローカル、最終回答は商用API
Gemma 4 × LiteRT × ツール ── スマホでもPCでもローカルLLMを動かす
2Bモデルがスマホで秒速50トークン出るって、すごい時代になったうさ🐰
Gemma 4 ── 「スマホで動くAI」の本命
Google DeepMindが2026年4月2日にリリースしたGemma 4は、ローカルLLM界の「事件」でした。Gemini 3と同じ研究基盤から生まれ、全モデルがApache 2.0ライセンス。
| モデル | パラメータ | 想定デバイス | メモリ目安 | コンテキスト |
|---|---|---|---|---|
| E2B | 2.3B | スマホ・IoT | 1.5GB未満 | 128K |
| E4B | 4.5B | スマホ上位機種 | 約3.7GB | 128K |
| 26B MoE(A4B) | 26B(実稼働3.8B) | ゲーミングPC | 約16GB | 256K |
| 31B Dense | 31B | ワークステーション | 約20GB+ | 256K |
Gemma 3から大きな変更点があります。
- ライセンス ── 独自ライセンスからApache 2.0へ。商用利用の制約がなくなった
- マルチモーダル ── テキスト・画像・音声・動画すべてに対応(E2B/E4Bは音声もネイティブ)
- 思考モード ── 複雑な問題を段階的に推論するThinking Mode搭載
- エージェント機能 ── ネイティブ関数呼び出し対応。外部ツールと連携できる
LiteRT-LM ── Googleが本気で作ったオンデバイス推論エンジン
「スマホでLLMを動かす」と聞くと実験的な印象があるかもしれませんが、LiteRT-LMは違います。Google AI Edgeが開発した本番向けフレームワークで、Chrome、Chromebook Plus、Pixel Watchですでに使われているプロダクション実績付きです。
対応プラットフォームも幅広いです。
- Android(GPU / NPU / CPU)
- iOS(GPU / CPU)
- Windows / Linux / macOS
- Raspberry Pi / IoTデバイス
- Web(WebGPU)
GPU(Vulkan / Metal / OpenGL)やNPU(Android Neural Networks API)のハードウェアアクセラレーションをフル活用するので、スマホの性能を最大限引き出せます。
AI Edge Gallery ── スマホで最速スタート
Google Playからインストール → モデルをダウンロード → 即使える。セットアップ所要時間は5分以下です。
- Google Playで「AI Edge Gallery」を検索してインストール
- アプリを開いてモデル(Gemma 4 E2Bなど)をダウンロード
- ダウンロード完了後、すぐにAIチャットが使える
初回のモデルダウンロードに数分かかりますが、一度ダウンロードすればオフラインでも使えます。Wi-Fi環境でのダウンロードがおすすめです🐰
法人向け生成AIサービス「ナレフルチャット」は、PCでもスマートフォンでも使えるマルチデバイス対応だから、オフィスでも外出先でもシームレスにAIを活用できます。ChatGPT、Gemini、Claudeなど主要プロバイダのAIモデルを用途に応じて使い分けることも可能です。
いつでも・どこでも・誰でも使えるAI環境を、まずは無料で体験してみませんか?初月無料のトライアルをご用意しておりますので、生成AIの利活用を検討している企業様は、ぜひ一度お試しください。【実機検証】Gemma 4 E2Bをスマホで試してみた
ベンチマークの数字だけじゃ分からない!スマホで動くローカルLLMの実力を確かめてみたうさ🐰
検証の狙い
以前の記事「Sakana Chat 日本発AIユニコーンが放つ「日本仕様」チャットAI」では、Sakana Chat(Namazu)・Claude・DeepSeekの3つのクラウドモデルを同じプロンプトで比較しました。
今回は同じプロンプトを使って、スマホ上で動くわずか2.3BのローカルLLM「Gemma 4 E2B」がどこまでやれるのかを検証します。推論速度が速いE2Bなら、スマホでもサクサク体感できます。クラウドモデルとの比較は上記の記事を参照してください。
検証環境
- アプリ ── Google AI Edge Gallery(Android)
- 検証端末 ── Pixel 10
- 検証モデル ── Gemma 4 E2B(2.3B effective、1.5GB未満)
ローカルLLMの検証なので、完全オフライン(機内モード)で実施しています。データは一切外部に送信されません。
検証1. 日本文化の深い理解
プロンプト
日本の「本音と建前」の文化について、ビジネスシーンでの具体例を3つ挙げて説明してください。海外の人が誤解しやすいポイントも教えてください。Gemma 4 E2Bの回答

「本音と建前」の定義を正確に説明した上で、「意見表明での異論の避け方」「評価フィードバックでの過度な肯定」「納期遅延の曖昧な報告」の3例を、それぞれ建前・本音・文化的機能の3層構造で丁寧に解説。海外の人が誤解しやすいポイントとして「曖昧さを非協力と誤解」「肯定的フィードバックを偽善と誤解」「合意形成プロセスを非効率と誤解」の3点を挙げ、それぞれ真意まで踏み込んだ説明を生成しました。
考察
2.3Bという小さなモデルにも関わらず、回答の構造化・網羅性ともに驚くほど高品質です。Sakana Chat記事のクラウドモデル(Sakana Chat/Claude/DeepSeek)と比較しても、情報の正確さと具体性で遜色ありません。むしろ「建前→本音→文化的機能」の3層構造は、クラウドモデルのどれよりも整理されていた印象です。スマホでオフラインで動く2Bモデルがこのレベルとは、正直驚きました🐰
検証2. 日本語の微妙なニュアンス理解
プロンプト
「結構です」という表現が肯定と否定の両方の意味を持つことを、具体的な会話例を使って説明してください。外国人が間違えやすい類似表現も紹介してください。Gemma 4 E2Bの回答
「結構です」の二つの意味(肯定=十分である / 否定=不要である)を明確に定義した上で、食事の勧め・本の勧め・頻繁な勧誘・過剰な要求の4つの会話例をシチュエーション別に提示。さらに「いいです」「結構(単独使用)」との違いを表形式で整理し、英語の”No”との混同や「結構」単独使用時の誤解ポイントまで解説しました。
考察

肯定と否定を分けた上で各4パターンの会話例を出し、さらに類似表現との比較表まで自発的に生成した点は高く評価できます。Sakana Chat記事でClaudeが示した「確認→肯定、申し出→否定」という実用的な判別ルールほどの切れ味はないものの、情報量と構造化のレベルはクラウドモデルに匹敵します。2Bモデルでここまで出せるのは素直にすごいです🐰
検証3. 日本特有の社会制度
プロンプト
日本のふるさと納税の仕組みを、メリット・デメリットを含めて説明してください。2026年現在の注意点があれば教えてください。Gemma 4 E2Bの回答
基本的な仕組み(寄付→控除→返礼品)を4ステップで整理し、メリット5点(税金控除、返礼品、地域貢献、地域とのつながり、節税効果)、デメリット・注意点7点(自己負担額、上限額、返礼品選択の難しさ、手続きの煩雑さ、控除上限額の把握、税額控除の仕組み理解、寄附金の認識)を網羅的に解説。2026年現在の注意点として「所得と上限額の再計算」「返礼品の品質確認」「各種控除との重複確認」「制度変更の監視」の4点を挙げ、最後に表形式のまとめを生成しました。
考察

ここでローカルLLMの特性がはっきり出ました。Sakana Chat記事では、Sakana ChatがWeb検索で総務省のソースリンク付きで「ポイント付与禁止(2025年10月〜)」「地場産品基準の厳格化(2026年10月〜)」といった具体的な制度改正を回答していました。Claudeも「6割ルール」「富裕層向け193万円上限」に言及。
一方、完全オフラインで動くGemma 4 E2Bは、制度の基本解説は正確ですが、2026年の具体的な改正内容には踏み込めていません。「制度変更の監視が重要」という一般的なアドバイスに留まっています。
これは弱点ではなくローカルLLMの性質です。学習データのカットオフ以降の情報は持っていないので、最新の制度改正はWeb検索付きのクラウドモデルに任せる。基礎知識の整理はローカルで十分── まさにハイブリッド運用が正解という好例です🐰
検証4. プログラミング能力
プロンプト
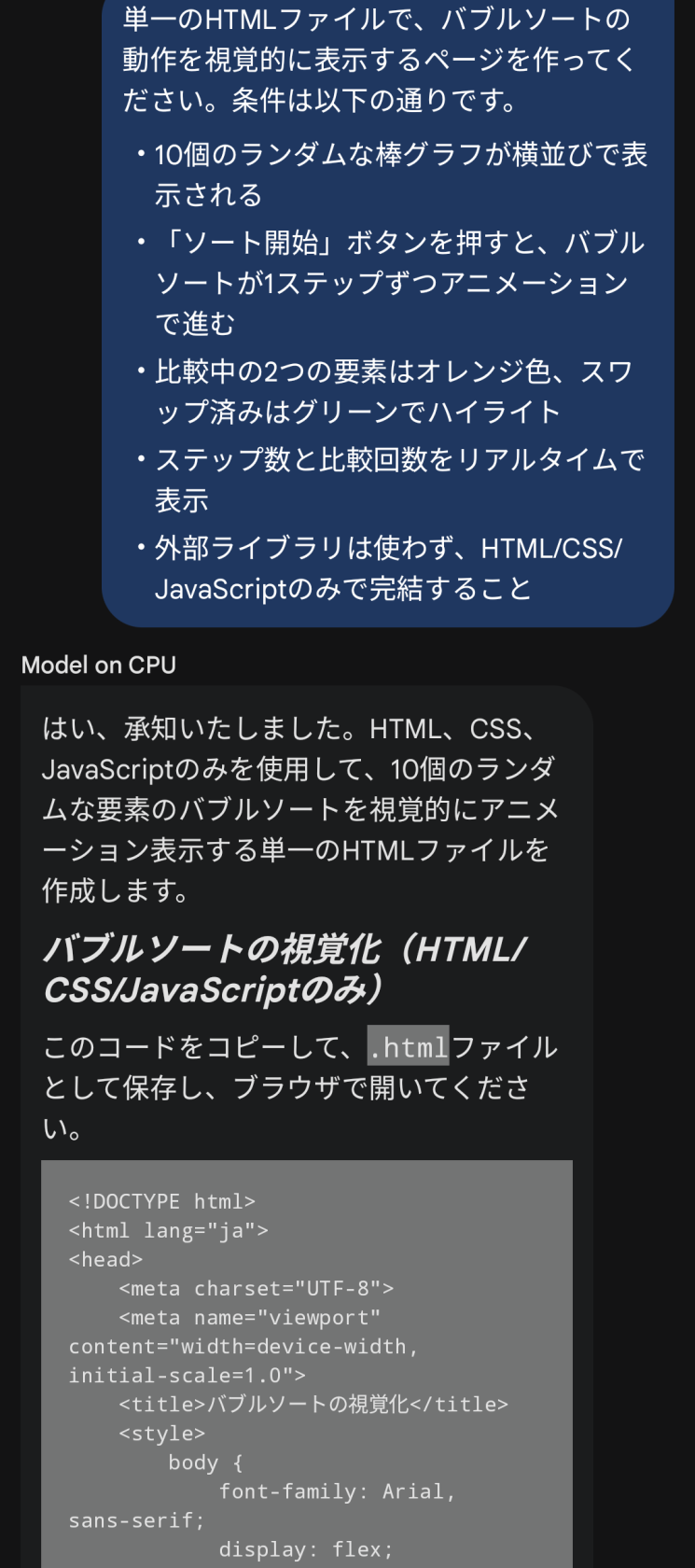
単一のHTMLファイルで、バブルソートの動作を視覚的に表示するページを作ってください。条件は以下の通りです。
- 10個のランダムな棒グラフが横並びで表示される
- 「ソート開始」ボタンを押すと、バブルソートが1ステップずつアニメーションで進む
- 比較中の2つの要素はオレンジ色、スワップ済みはグリーンでハイライト
- ステップ数と比較回数をリアルタイムで表示
- 外部ライブラリは使わず、HTML/CSS/JavaScriptのみで完結することGemma 4 E2Bの回答
HTML/CSS/JavaScriptの構造は正しく分離され、バブルソートのロジック、比較中のオレンジ色ハイライト、スワップ済みのグリーン表示、ステップ数・比較回数のカウンターなど、プロンプトの要件をすべて盛り込んだコードを生成しました。コードの解説まで丁寧に付けてくれています。
しかし、実際にブラウザで動かすと棒グラフが一切表示されませんでした。
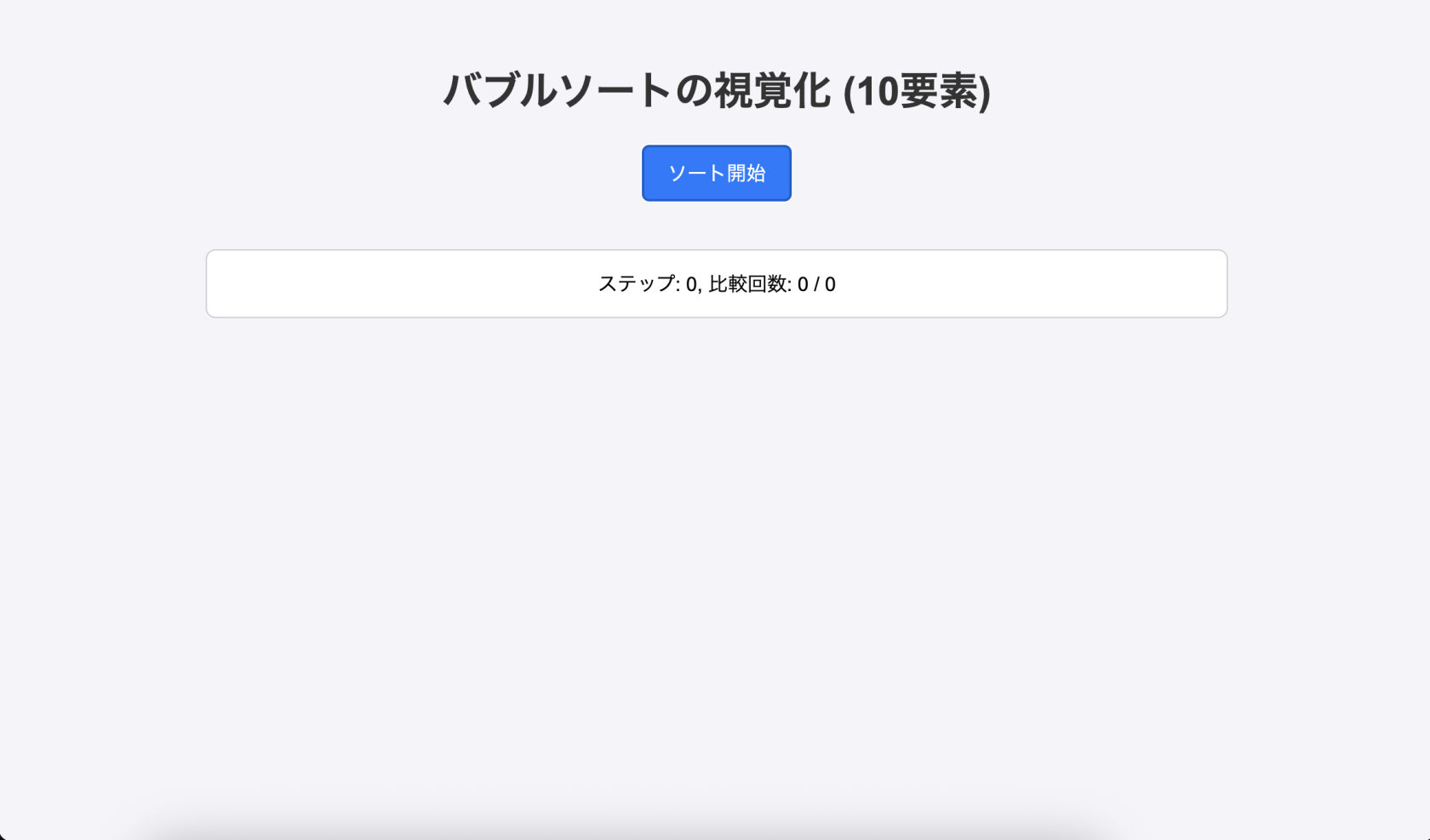
UIのガワ(タイトル、ボタン、ステータス表示)は正常に描画されていますが、肝心の棒グラフが空っぽ。initializeArray()内のランダム値生成ロジックでMAX_HEIGHTとINITIAL_HEIGHT_RANGEの計算が矛盾しており、棒の高さが正しく生成されないバグが原因です。
考察
Sakana Chat記事では、Sakana Chat(DeepSeekベース)も同様に自動進行が実装できず、Claudeだけが完璧に動作していました。今回のGemma 4 E2Bも「コードの構造は理解しているが、動くコードを生成するには至らない」という結果に。
これは2Bモデルの限界というより、コーディングタスクの難しさを示しています。UI生成のようなフロントエンド実装は、複数の要素(DOM操作、非同期処理、CSSアニメーション)を正確に連携させる必要があり、小〜中規模のモデルには厳しい領域です。コーディングは素直に商用モデル(Claude、GPT)やコーディング特化モデル(Qwen3-Coder-Next等)に任せるのが賢い選択です🐰
検証まとめ
| 検証項目 | Gemma 4 E2B(ローカル) | 参考 Sakana Chat | 参考 Claude | 参考 DeepSeek |
|---|---|---|---|---|
| 日本文化の理解 | ◎ 3層構造で整理 | ◎ 網羅的 | ◎ 簡潔で実践的 | ◎ 独自の視点 |
| 日本語ニュアンス | ◎ 会話例+比較表 | ◎ ソースリンク付き | ◎ 判別ルール明確 | ○ 文法的視点 |
| 日本固有制度 | ○ 基礎は正確、最新情報なし | ◎ 総務省リンク付き | ○ 幅広い改正点 | ○ 計算式まで詳細 |
| プログラミング | ✕ 構造は正しいが動作せず | △ バグあり | ◎ 完璧な動作 | ○ UXに課題 |
参考列のSakana Chat・Claude・DeepSeekの結果は「Sakana Chat記事」で詳しく解説しています🐰
所感
正直、2.3Bのスマホモデルがここまで戦えるとは思っていませんでした。日本文化や日本語ニュアンスの解説では、クラウドモデルと比較しても遜色ないどころか、構造化の面では上回る場面すらありました。
一方で、最新情報が必要なテーマ(制度改正など)はオフラインモデルの限界がはっきり出ますし、プログラミングは現時点では厳しいです。
結論 ── 「日常の質問はローカル、最新情報と高度なコーディングはクラウド」。このハイブリッド運用が、2026年のベストプラクティスだと実感しました🐰
まとめ ── あなたに合ったローカルLLMはこれ
正直に言うと、最初はこう思っていました。「ローカルLLMは上級者のおもちゃでしょ、実用性はまだまだ」って。
でも、Gemma 4がスマホでサクサク動いているのを見て、認識がガラッと変わりました。Qwen3.5の日本語品質は「これ無料でいいの?」というレベルだし、Kimi K2.5はGPT-5.2を超えるスコアまで出している。
2026年は「ローカルLLM元年」だと思います。
まずはAI Edge GalleryかOllamaで、5分で体験してみてください。
思ったより簡単に、思ったより賢い。それが今のローカルLLMです🐰
あなたも生成AIの活用、始めてみませんか?
生成AIを使った業務効率化を、今すぐ始めるなら
「初月基本料0円」「ユーザ数無制限」のナレフルチャット!
生成AIの利用方法を学べる「公式動画」や、「プロンプトの自動生成機能」を使えば
知識ゼロの状態からでも、スムーズに生成AIの活用を始められます。
taku_sid
https://x.com/taku_sid
AIエージェントマネジメント事務所「r488it」を創立し、うさぎエージェントをはじめとする新世代のタレントマネジメント事業を展開。AI技術とクリエイティブ表現の新たな可能性を探求しながら、次世代のエンターテインメント産業の構築に取り組んでいます。
ブログでは一つのテーマから多角的な視点を展開し、読者に新しい発見と気づきを提供するアプローチで、テックブログやコンテンツ制作に取り組んでいます。「知りたい」という人間の本能的な衝動を大切にし、技術の進歩を身近で親しみやすいものとして伝えることをミッションとしています。








スマートフォンでもAI活用!
アプリ版「ナレフルチャット」配信中
iPhoneはこちら


Androidはこちら




